BFS (Breadth-First Search)
(DFS에 이어 작성한 post 입니다. 먼저 DFS를 읽고 오시는 것을 권장합니다.)
BFS (Breadth-First Search)는 search algorithm 종류 중 하나입니다. DFS의 단점 중 하나는 항상 optimal solution을 찾는 것이 아니라는 것입니다. BFS는 이런 점을 보완한 search alogirithm 입니다. 전반적으로 DFS와 유사하므로 동일한 부분은 생략하고 차이나는 부분 위주로 살펴보겠습니다.
BFS process는 다음과 같습니다. Frontier는 initial state(A)를 포함한 상태, explored set은 empty 상태로 시작합니다.
Frontier에 search할 next node 확인: Frontier에 search할 next node가 존재하는지 확인합니다. 만약 없다면 solution이 없음을 의미하며 DFS process를 종료합니다. 참고로 여기서 언급한 node는 state, parent node, action, path cost 정보를 담고 있는 data structure입니다.
Next node 가져오기: Frontier에서 first node를 추출합니다. (queue structure)
Solution 확인과 return: 2번의 node가 goal test를 통과하면 search process를 종료하고 explored set을 solution으로 정의한 뒤 return합니다.
Explored set에 node 추가: 2번의 node가 goal test를 통과하지 못하면 explored set에 node를 추가합니다.
Frontier expansion: Frontier에 child node를 추가 합니다. 이 때 child node가 frontier와 explore set에 이미 존재하는지 확인합니다.
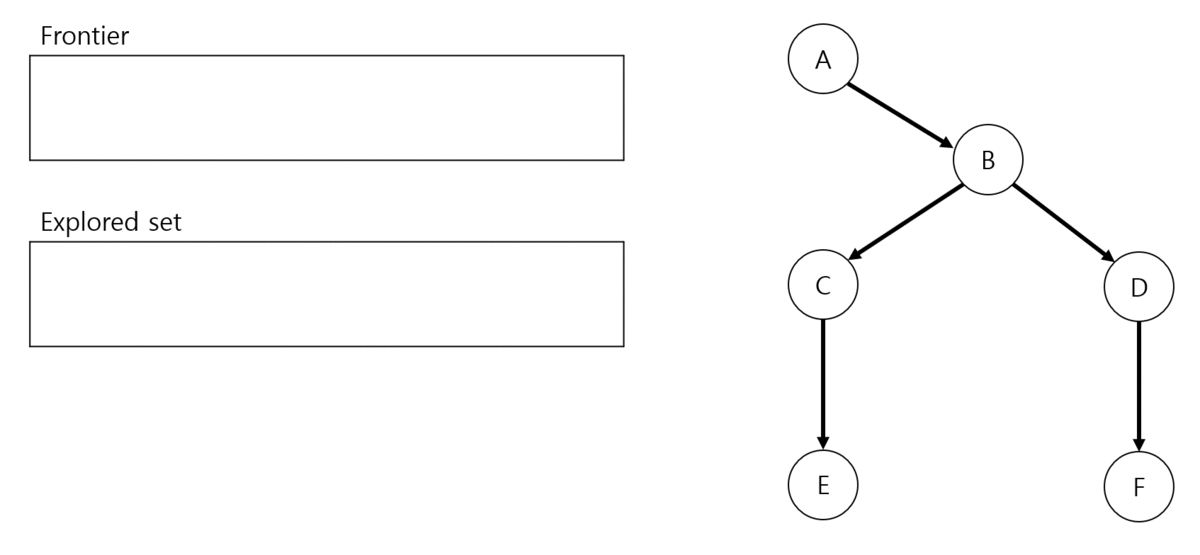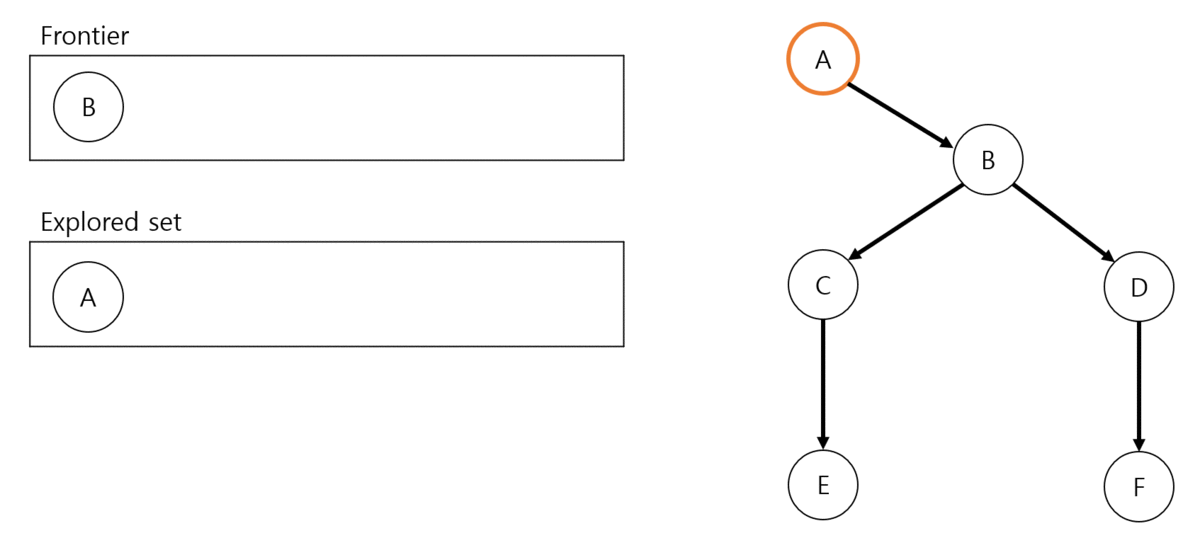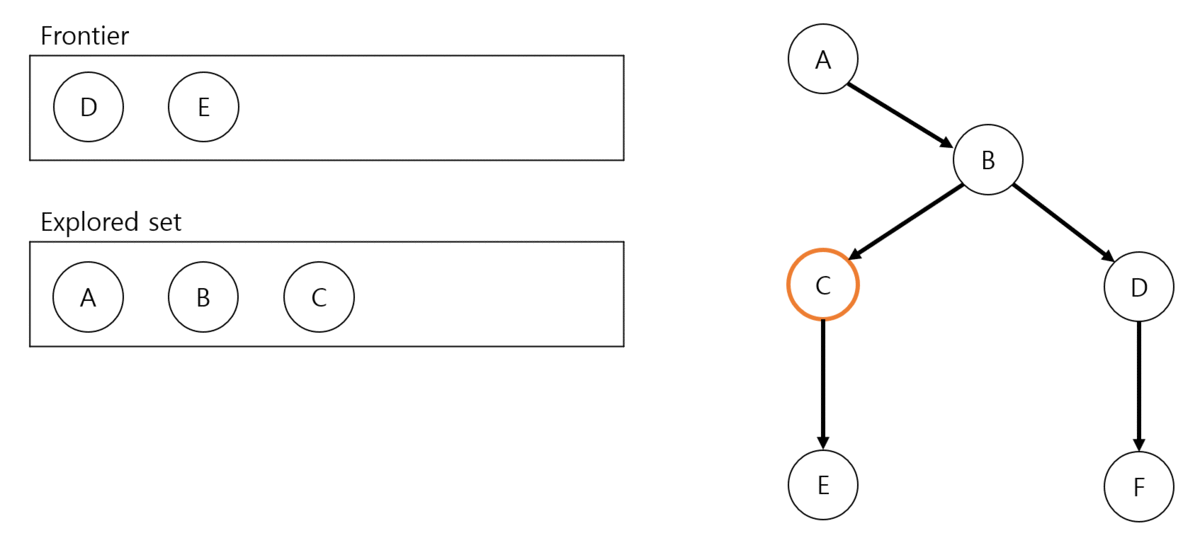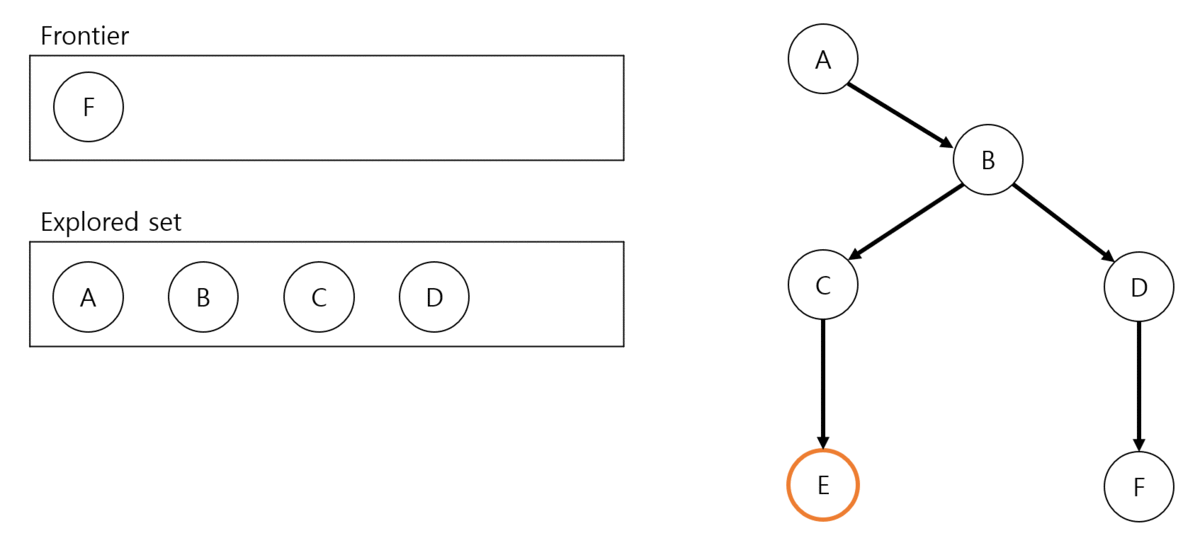 BFS process
BFS process
DFS와 차이점을 찾으셨나요? DFS는 search 과정에서 goal node(F)를 만날 때까지 계속 child node를 찾아갑니다. 하지만 BFS는 같은 depth의 모든 node(C, D)를 우선 찾아갑니다.
BFS 공간 복잡도, 시간 복잡도
Node의 수를 V(Vertex), 연결선의 수를 E(Edge)라고 할 때,
BFS의 공간 복잡도는 다음과 같습니다.
인접 행렬인 경우: O($V^2$)
인접 리스트인 경우: O(V+E)
시간 복잡도는 다음과 같습니다.
인접 행렬인 경우: O($V^2$)
인접 리스트인 경우: O(V+E)
DFS 장/단점
BFS의 장점은 다음과 같습니다.
- 여러 개의 solution이 존재할 경우 optimal solution을 찾을 수 있습니다.
BFS의 단점은 다음과 같습니다.
Search 해야 할 node가 많은 경우 필요 없는 node까지 모두 저장해야 하므로 DFS보다 큰 저장공간이 필요합니다.
Node의 수가 많을 수록 search 시간이 오래 걸립니다.
BFS 적용
BFS를 미로 문제에 적용해 보겠습니다.
‘QueueFrontier’ class는 ‘StackFrontier’ class를 상속 받습니다. 다만 DFS와 차이점은 BFS가 queue structure를 사용하기 때문에 ‘remove’ function이 frontier에서 node를 가져올 때 가장 첫 번째 위치에 존재하는 node를 가져온다는 점입니다. 그 외 code는 DFS와 동일합니다.
1
node = self.frontier[0]
BFS 예제
미로 문제를 입력받아 solution을 찾아내는 과정입니다. 전체 code와 예제 파일은 이 곳에서 확인할 수 있습니다.
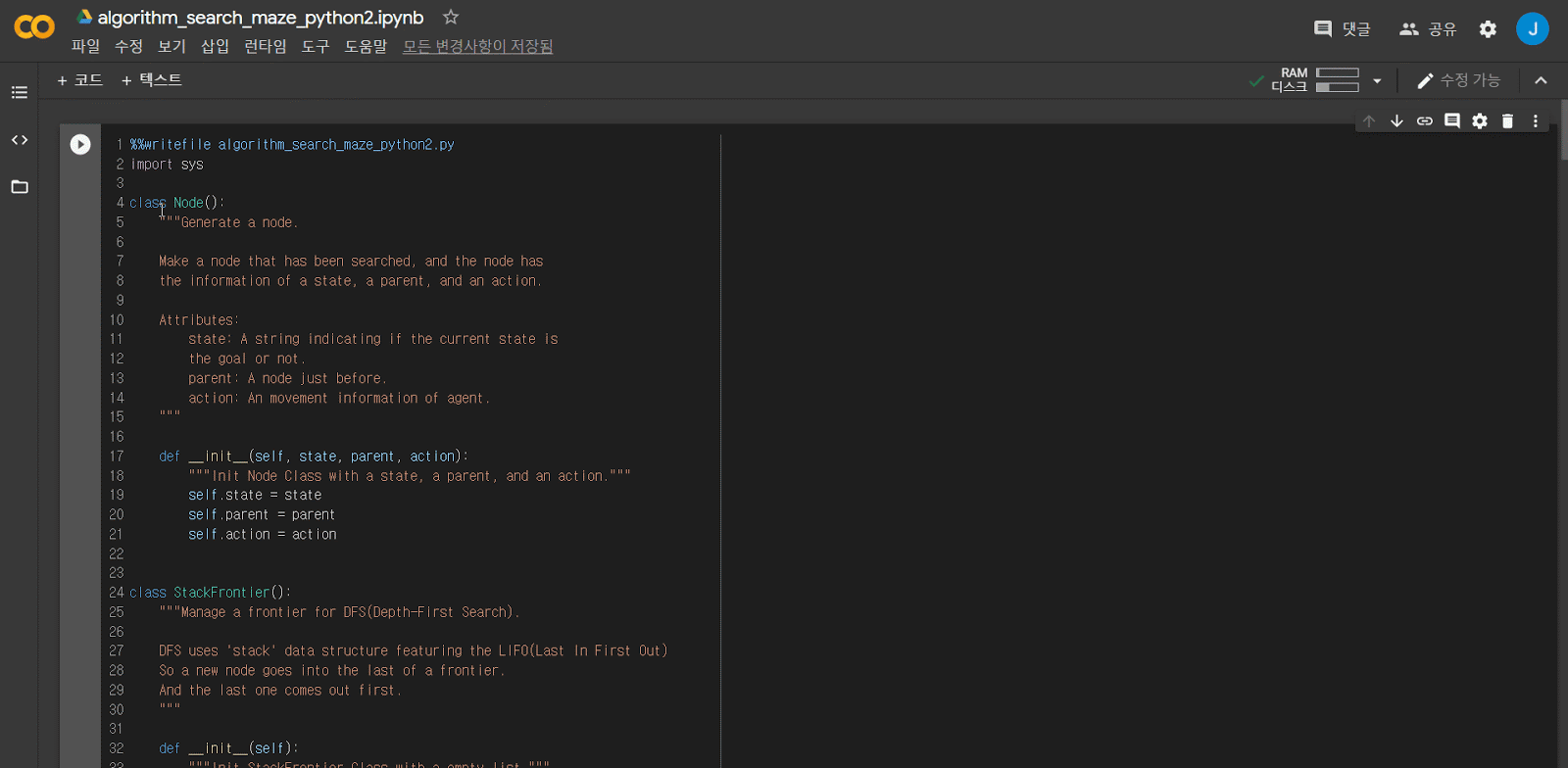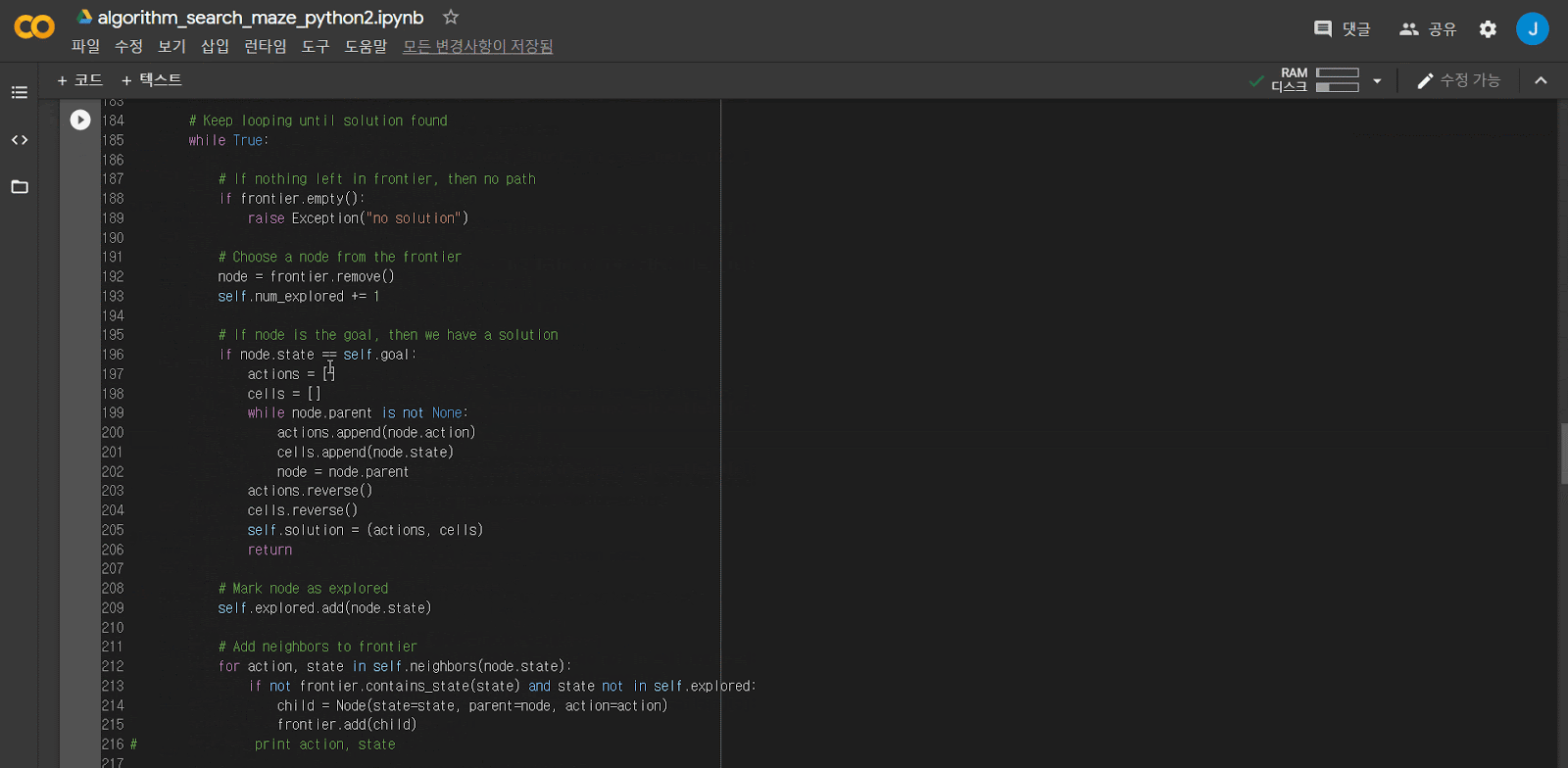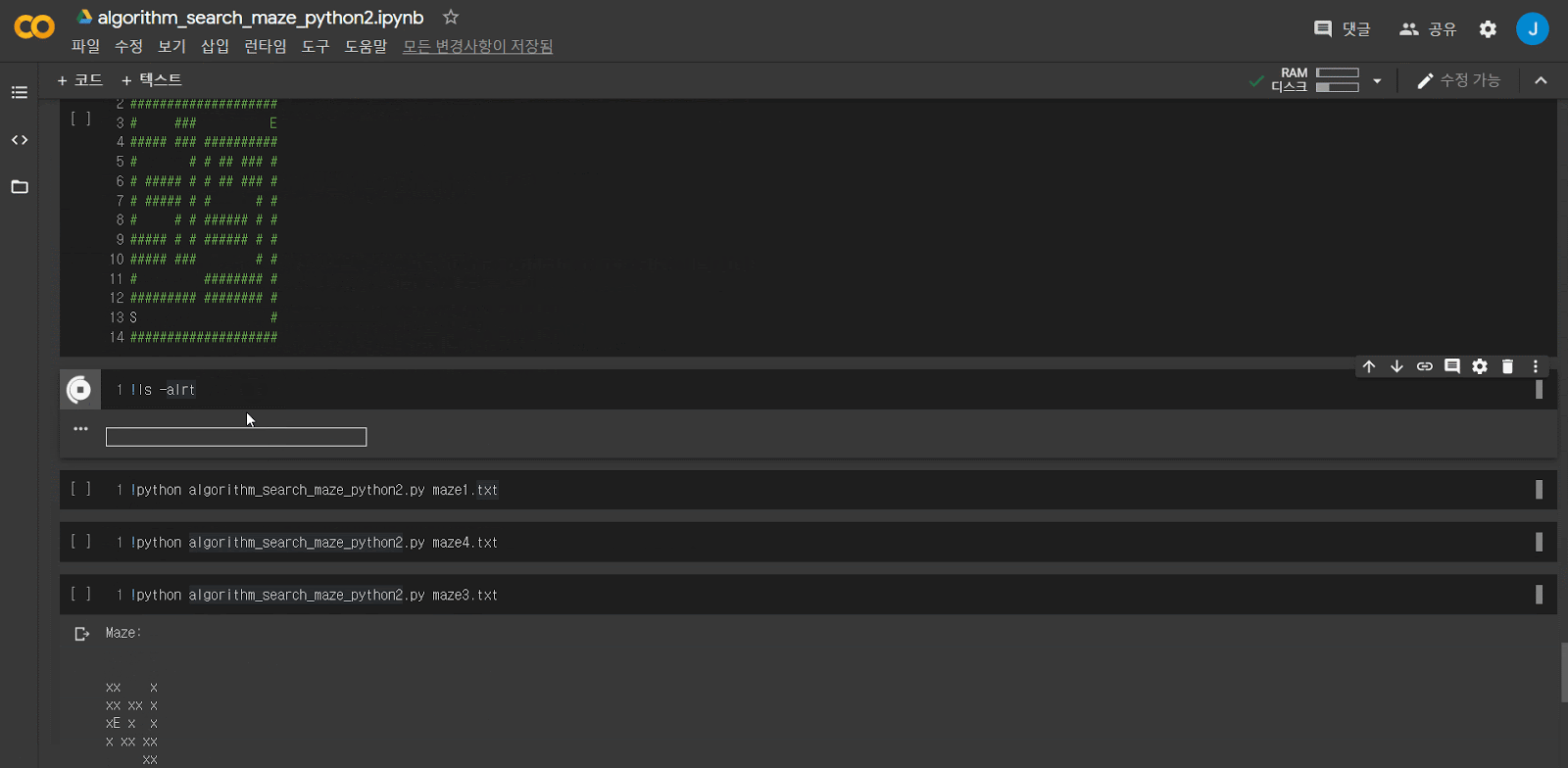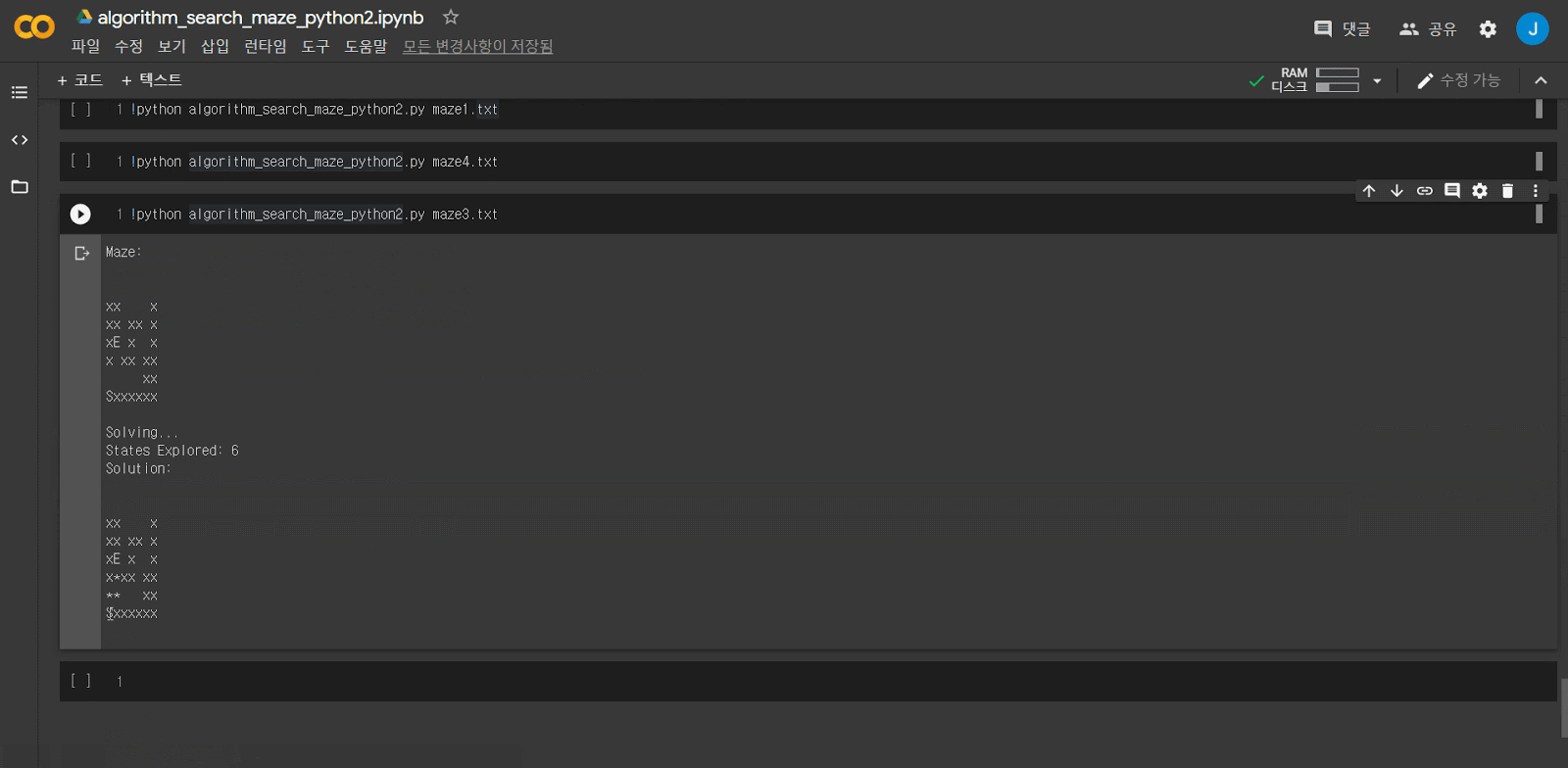 BFS 미로 문제 예제
BFS 미로 문제 예제
DFS 방식으로 미로 문제를 풀 때 optimal solution이 아닌 멀리 돌아가는 solution을 return한 case가 있었습니다. BFS 방식을 적용하면 optimal solution을 return 합니다.