본 post는 국가생명연구자원정보센터(KOBIC) 주관 경희대학교 이과대학 김권일 교수님의 생물정보학 동향을 정리한 내용입니다.
Intro
Machine learning 관련 기초 개념을 확인하고, 공개된 논문내용 및 데이터를 바탕으로 직접 실습하고 학습하는 과정입니다.
생물정보학(Bioinformatics)이란?
생물정보학(Bioinformatics)은 생물학적인 문제를 이해하기 위한 방법이나 프로그램을 개발하는 학제간 분야를 아우르는 학문입니다.
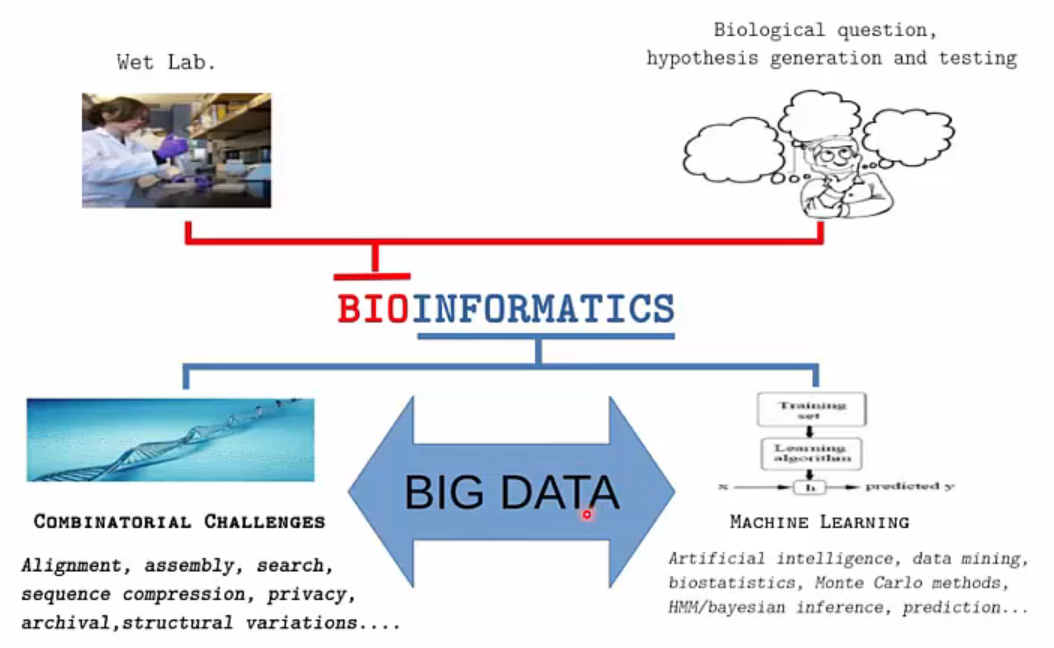 생물정보학 개념
생물정보학 개념
https://www.edwith.org/deep-learning-2023/lecture/1475083
생물정보학의 주요한 연구대상은 DNA입니다. DNA는 대상의 환경, 경험, 형태에 대한 정보를 담고 있습니다. Central Dogma라고 일컫는 일련의 과정(DNA → RNA → Protein)을 통해 DNA에 담긴 정보가 발현됩니다.
DNA 염기서열 분석기술은 HGP(Human Genome Project) 이후 꾸준히 발달해 왔습니다. HGP는 30억 쌍의 인간 유전체를 해독한 대형 프로젝트로, 방대한 데이터를 다루면서 자연스럽게 염기서열 분석기술의 발전을 이끌었습니다. 특히 2007~2008년 경 염기서열 분석 비용이 급진적으로 하락하면서 무어의 법칙을 넘어서기 시작하는데, 바로 NGS(Next Genration Sequencing)가 본격적으로 시작된 시기입니다.
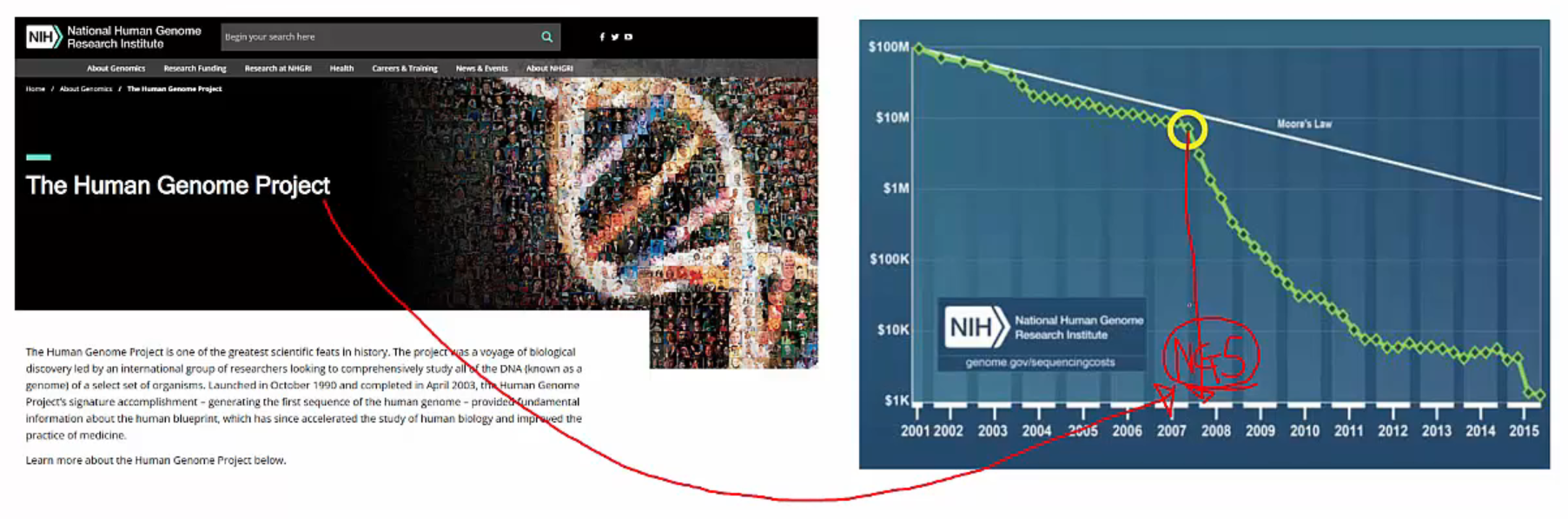 HGP와 NGS의 시작
HGP와 NGS의 시작
https://www.edwith.org/deep-learning-2023/lecture/1475083
이러한 immune system을 활용하여 tumor cell을 제거하기 위해서는, normal cell에는 존재하지 않고 tumor cell에만 존재하는 specific antigen을 목표로 삼는 것이 좋습니다. TSA(Tumor Specific Antigen)는 tumor cell에 특이적인 antigen을 의미하며, TAA(Tumor Associated Antigen)는 일부 normal cell에도 존재하지만 대부분 tumor cell에서 나타나는 antigen을 의미합니다.
PCR vs. NGS
Conventional PCR은 염기서열 분석이 필요한 특정 구간을 선별하여 분석하므로 많은 시간과 노력이 필요합니다. 이에 반해 NGS는 화학시료와 광학기술을 활용하여 인간 유전체 전체 부위를 동시다발적으로 분석하는 기술로 비교적 적은 시간과 노력을 들이고 비용의 감소를 불러왔습니다.
 PCR vs. NGS
PCR vs. NGS
https://www.edwith.org/deep-learning-2023/lecture/1475083
NGS의 시작과 함께 DNA는 big data 수준으로 축적되어 가고 있습니다. 빅데이터는 3V로 요약할 수 있는데, 데이터의 양(Volume), 데이터 생성 속도(Velocity), 형태의 다양성(Variety)을 의미합니다. 2020년 Nebula Genomics는 한 사람의 WGS data를 $299에 제공하고 있습니다.
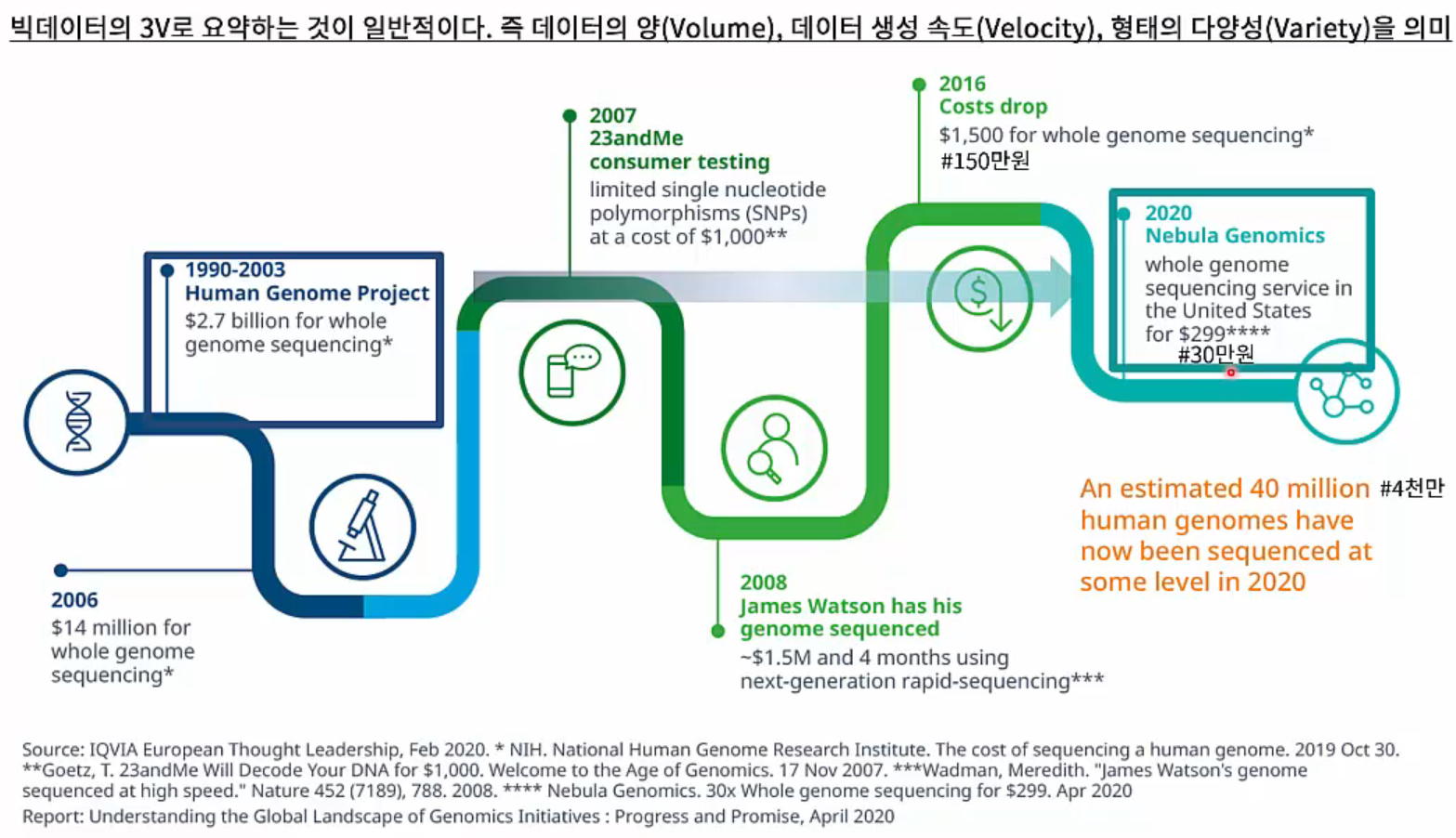 DNA is Big data
DNA is Big data
https://www.edwith.org/deep-learning-2023/lecture/1475083
또한 염기서열 분석기술의 발전은 한 명의 한 개 유전자를 분석하는 수준에서 여러 명의 여러 유전자를 분석하는 것으로 발전했습니다. (유전체학, Genomics) 그 뿐만 아니라 Epigenomics, Transcriptomics, Proteomics, Metabolomics 등 Genomics와 연관된 다양한 학문 분야로 발전했습니다.
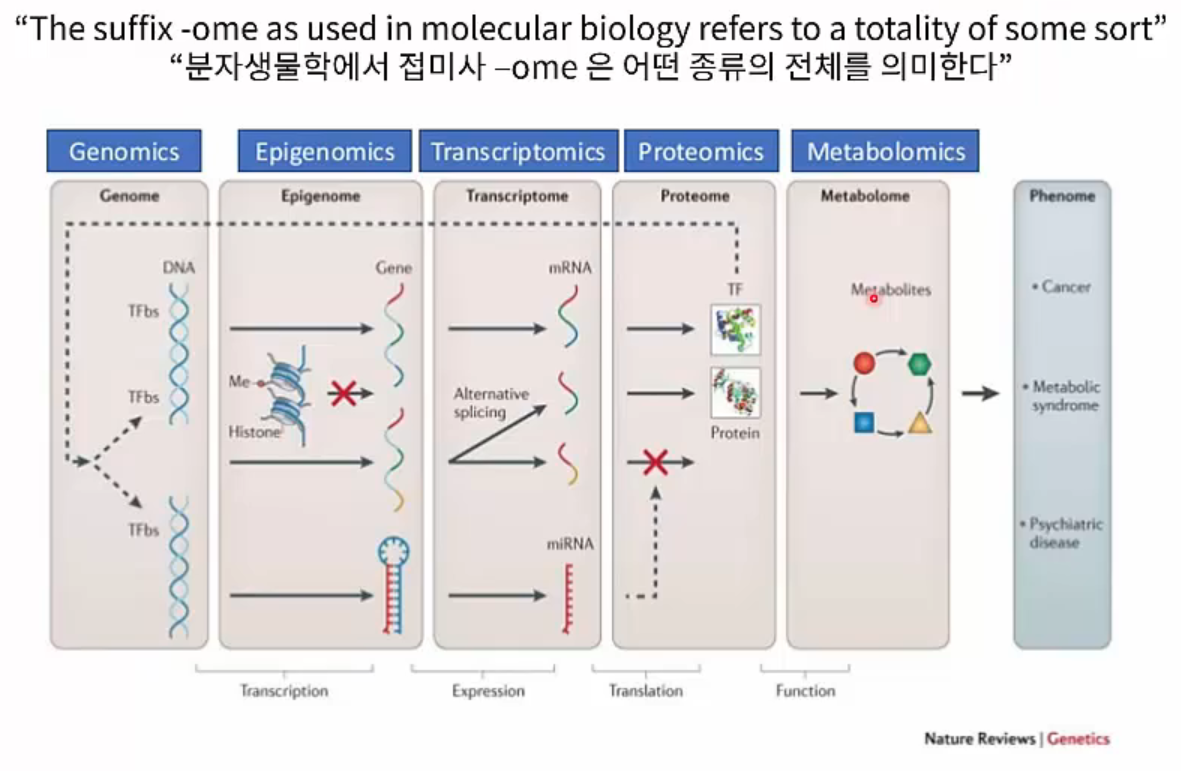 NGS와 -omics 연구의 발전
NGS와 -omics 연구의 발전
https://www.edwith.org/deep-learning-2023/lecture/1475083
AlphaFold를 사용한 Proteomics data 분석
2021년 구글 딥마인드가 발표한 Protein 구조 예측 인공지능 AlphaFold2는 인간 Protein 3D 구조 data 갯수를 20,296개(전체의 98.5% 수준)로 늘렸습니다. 이는 지금까지 실험을 통하여 확인된 3,500여개(전체의 17% 수준)에 비해 매우 증가된 수치입니다.
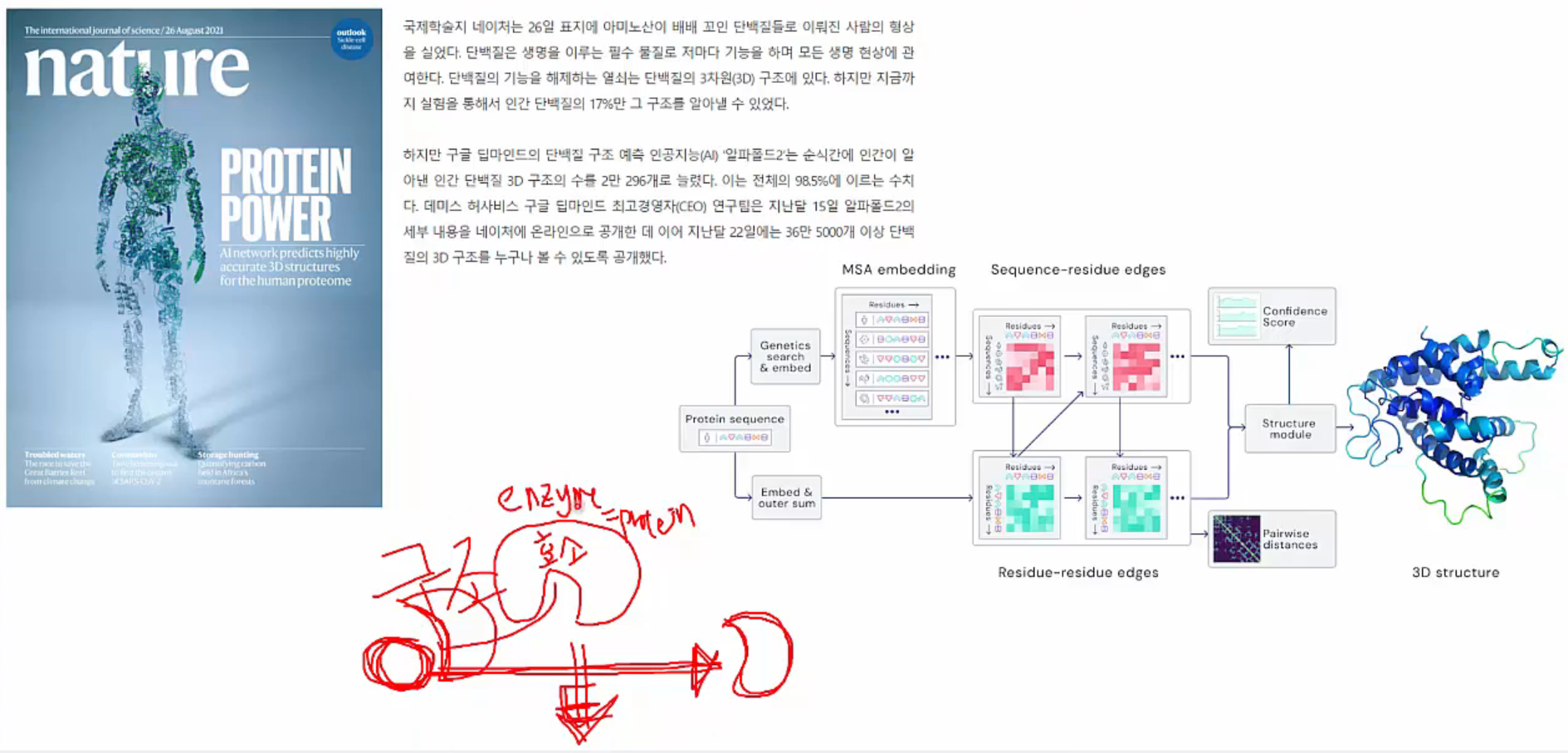 AlphaFold2
AlphaFold2
https://www.edwith.org/deep-learning-2023/lecture/1475083
Take Home Message
생물정보학은 생물학과 관련된 모든 문제들을 이해하기 위한 방법론을 다루고, 학제간 분야를 아우르는 학문입니다. 생물학과 더불어 전산학, 통계학의 통합적 이해를 요구합니다.
생물정보를 담고 있는 DNA 염기서열이 주 연구대상 중 하나이고, NGS 발전에 따라 Genomics, Epigenomics, Transcriptomics, Proteomics 등 주요한 생물학 분야의 문제들을 해결하는데 필수불가결한 요소가 되고 있습니다.
최근 omics big data가 출현함에 따라 다양한 machine learning 및 deep learning을 수행하여 해결하기 힘든 각종 생물학 난제들을 풀어나가려는 시도가 이루어지고 있습니다.