본 post는 국가생명연구자원정보센터(KOBIC) 주관 경희대학교 이과대학 김권일 교수님의 기계학습 기초 개념 및 평가 방법을 정리한 내용입니다.
Intro
Machine learning 관련 기초 개념을 확인하고, 공개된 논문내용 및 데이터를 바탕으로 직접 실습하고 학습하는 과정입니다.
기계학습(Machine Learning)이란?
기계학습(Machine Learning)이란 컴퓨터로 경험을 활용해 시스템을 개선해 나가는 방법론입니다. 컴퓨터 시스템에서 일반적으로 경험은 data 형식으로 존재합니다. 컴퓨터를 활용해 data에서 하나의 model을 만들어내는 learning algorithm입니다. 즉, model이란 data를 대상으로 learning algorithm이 학습한 결과물 입니다. 이러한 model은 새로운 상황에 대면했을 때 이에 상응하는 판단을 제공합니다.
예를 들어 다음과 같이 수박에 관한 데이터가 존재합니다.
- 수박1: (색깔=청록; 꼭지모양=말림; 소리=혼탁함)
- 수박2: (색깔=진녹색 꼭지모양=약간 말림; 소리=둔탁함)
- 수박3: (색깔=연녹색; 꼭지모양=곧음; 소리=맑음)
수박에 관한 데이터의 집합을 data set, 각 기록은 하나의 대상에 대한 묘사이고 이 대상을 instance(사례) 혹은 sample, 색깔, 소리 등 대상의 성질을 반영하는 것을 attribute(속성) 혹은 feature(특성), 청록색, 진녹색, 연녹색 등 feature에 대해 취할 수 있는 값을 attribute value 혹은 feature value, 이러한 feature value가 sample별로 투영되어 잇는 공간을 sample space 라고 지칭합니다.
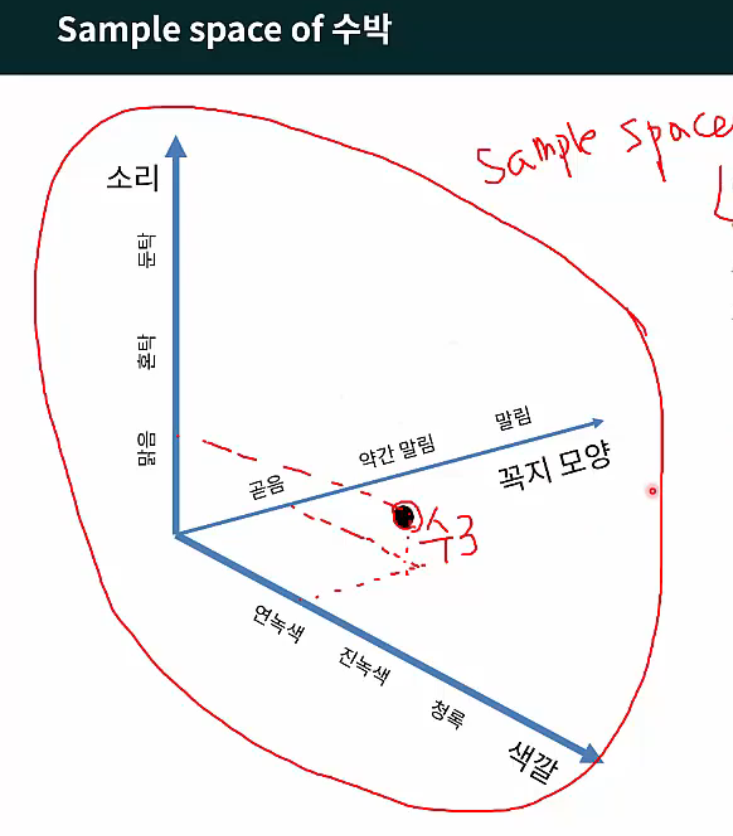 Sample Space
Sample Space
https://www.edwith.org/deep-learning-2023/lecture/1475084
Data set의 feature 수는 차원수(dimensionality)를 결정합니다.
Training
Training 혹은 learning은 data를 통해 model을 만들어가는 과정을 의미합니다. Model training 과정은 data를 통해 hypothesis를 세우고 잠재되어 있는 규칙을 찾아내는 과정입니다. (data-driven hypothesis)
하지만 data의 feature만으로는 유용한 결과를 얻어낼 수 없습니다. Label이라는 결과를 나타내는 정보가 필요합니다.
만약 우리가 예측하려는 값이 ‘잘 익은 수박’, ‘덜 익은 수박’과 같은 discrete value(이산값; 비연속적인 값)일 경우, 이러한 학습 문제를 classification이라고 합니다.
반대로 예측하려는 값이 수박의 당도를 나타내는 수치 ‘0.95’, ‘0.37’과 같은 continuous value(연속값)일 경우, 이러한 학습 문제를 regression이라고 합니다.
Testing
Model training 후, 해당 model을 활용하여 예측하는 과정을 testing이라고 합니다. 기계학습의 목표는 training set에서 좋은 성능을 나타내는 것이 아니라, 새로운 sample과 data에 적용되고 좋은 퍼포먼스를 내는 것입니다. 이런 경우를 generalization(일반화)가 잘 되었다고 이야기 합니다.
Error
Model의 예측 값과 sample의 실제 값 사이의 차이를 error라고 합니다.
Error rate(오차율): 전체 sample 수와 잘못 분류한 샘플 수의 비율
Accuracy(정밀도): 1 - 오차율
Machine learning으로 하고 싶은 궁극적인 목표는 testing error가 가장 작은 model을 만들어 내는 것입니다. 하지만 보통 대부분 model이 training erorr가 매우 작고 training sample에서 좋은 성능을 보여주지만 testing error는 그렇지 못한 경우가 많습니다.
Overfitting and Underfitting
새로운 sample data를 대상으로 좋은 퍼포먼스를 발휘하기 위해서는 model이 training data에서 보편규칙을 찾아야 합니다. 그러나 model이 training data에서 학습을 과도하게 잘하면 training data에만 내재된 특정 특성을 모든 data에 내재된 일반적인 성질로 오해하게 됩니다. 즉, generalization 성능이 떨어지고 이러한 현상을 overfitting(과적합)이라고 합니다. 이와 반대되는 개념은 underfitting(과소적합)이라고 하며 model이 training data의 일반 성질을 제대로 학습하지 못했다는 것을 의미합니다.
Underfitting은 algorithm을 더욱 견고하게 잘 만들면 해결될 수 있습니다.
하지만 Overfitting은 다루기가 매우 까다롭습니다. ML이 넘어야 할 핵심 장애물 입니다. 모든 learning algorithm은 overfitting을 방지하기 위한 장치를 갖고 있음에도 불구하고 overfitting을 피할 수 없으며, 단지 이를 완화하고 위험을 최소화하는 것에 만족해야 합니다.
기계학습 평가 방법
대부분 learning algorithm은 조율해야하는 parameter가 있으며, 두 종류가 존재합니다.
Hyper-parameter: algorithm의 parameter이며 일반적으로 10개 이내 입니다. Model의 구조 전반에 대한 parameter입니다. (산)
Model-parameter: model의 parameter이며 개수가 매우 많을 수 있습니다. (나무)
Parameter를 어떻게 설정하는가에 따라 model의 성능은 큰 차이를 보입니다. 따라서 model testing 및 model selection 시 learning algorithm의 선택 뿐만 아니라 algorithm parameter에 대한 설정도 고려해야 합니다. 이러한 과정을 parameter tuning이라고 합니다.
최적의 model을 얻기 위해서 어떤 learning algorithm을 사용해야 하고, 어떤 parameter를 선택해야 하는지 결정해야 하는데, 이를 model selection이라고 합니다.
이상적인 해답은 testing error를 기준으로 평가하여 가장 작은 model를 선택하는 것입니다. 이를 위하여 training set에서 일부를 testing에 사용합니다. 이 때 주의애햐 할 점은 training set에서의 testing set과 training set의 중복을 최대한 피해야 합니다.
Validation Set
m개의 sample을 가진 data set D가 있을 때, 적절히 처리하여 training set S와 testing set T로 나눠야 합니다. 새로운 sample에 대한 testing set과 구분하여 위 testing set을 validation set으로 부릅니다. 많은 연구에서 이 용어를 혼용하여 사용하는데 확실하게 구분하여 사용해야 합니다.
Cross Validation
Cross validation(교차 검증)은 data set D를 k개의 disjoing set(서로소 조합; mutually exclusive)으로 나누는 것으로 시작합니다. 개별 부분집합 D는 되도록 전체 data의 lebel 분포를 반영하도록 나눕니다. 그리고 k-1개의 부분집합들을 training set으로 사용하고, 나머지 한 개의 부분집합을 testing set으로 사용합니다. 이렇게 하면 k개의 training/testing set이 만들어지고, k번의 training과 testing을 거쳐 k개의 testing 결과값 평균을 얻을 수 있습니다. Cross validation을 통한 testing 결과의 안정성과 정확도는 k값에 따라 달라집니다. 이러한 점을 강조하기 위해 k-fild cross validation이라 부르며, 일반적으로 k=10으로 두고 10-fold cross validation을 많이 사용합니다.
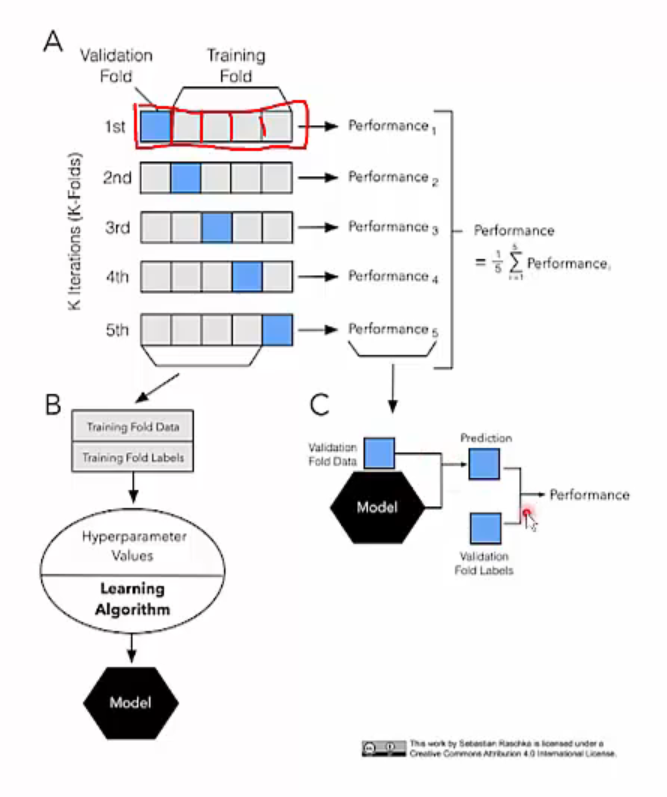 5-fold Cross Validation
5-fold Cross Validation
https://www.edwith.org/deep-learning-2023/lecture/1475084
Model Performance Measure
Model으 generalization 성능을 평가하는 기준을 performance measure(성능 측정)이라고 합니다. 이는 프로젝트 목적을 반영해야 하는데, 서로 다른 model의 성능을 비교할 때 일관되지 않은 성능 측도를 사용한다면 판단이 힘들 것입니다. 즉, 어떤 model이 좋은 model인지 결정하는 것은 algorithm과 data가 아닌 data 분석 목적에 달려 있습니다.
Recall, Precision and F1 Scroe
Error rate(ERR) = (FN+FP) / (전체 data 수=P+N) : 전체 수박 중 잘못 분류한 비율
Precision(PREC) = TP / (TP+FP) : 잘 익었다고 판단한 수박 중에 실제 잘 익은 수박의 비율
Recall(Sensitivity) = TP / (TP+FN) : 모든 잘 익은 수박 중에 잘 선택된 비율
Error rate와 accuracy는 자주 사용되지만 모든 문제에 활용되지는 못합니다. 우리가 알고 싶은 것은 ‘골라낸 수박 중에 잘 익은 수박의 비율’, 혹은 ‘모든 잘 익은 수박 중에 잘 선택된 비율’일 수 있기 때문입니다. 이러한 판단에 대해서 error rate는 도움을 줄 수 없으며, Precision(정밀도)와 recall(재현율)이 이러한 요구에 맞는 성능 측도입니다.
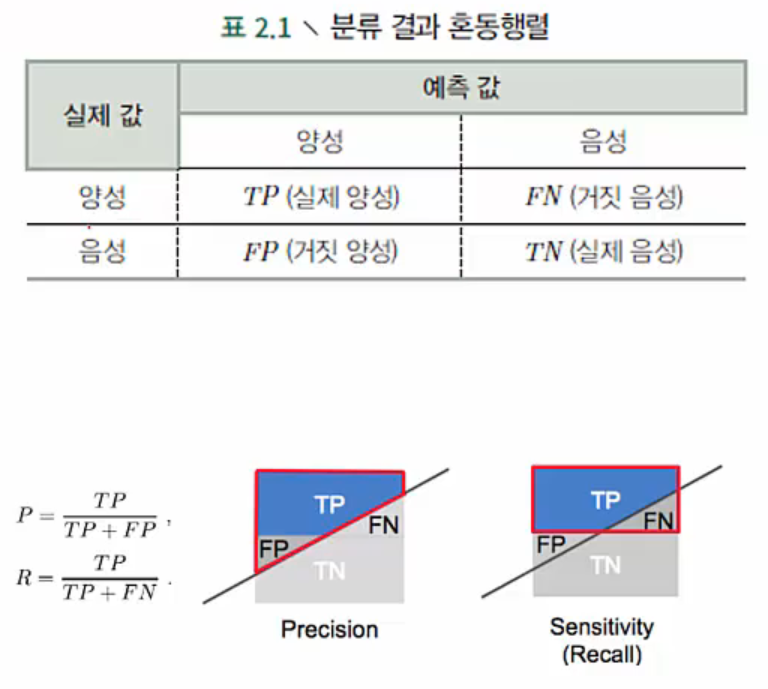 Confusion Matrix
Confusion Matrix
https://www.edwith.org/deep-learning-2023/lecture/1475084
Precision과 rcall 사이에는 trade-off가 존재합니다. 일반적으로 precision이 높으면 recall이 낮고(녹색 점선), recall이 높으면 precision이 낮은 경우(파란색 점선)가 많습니다.
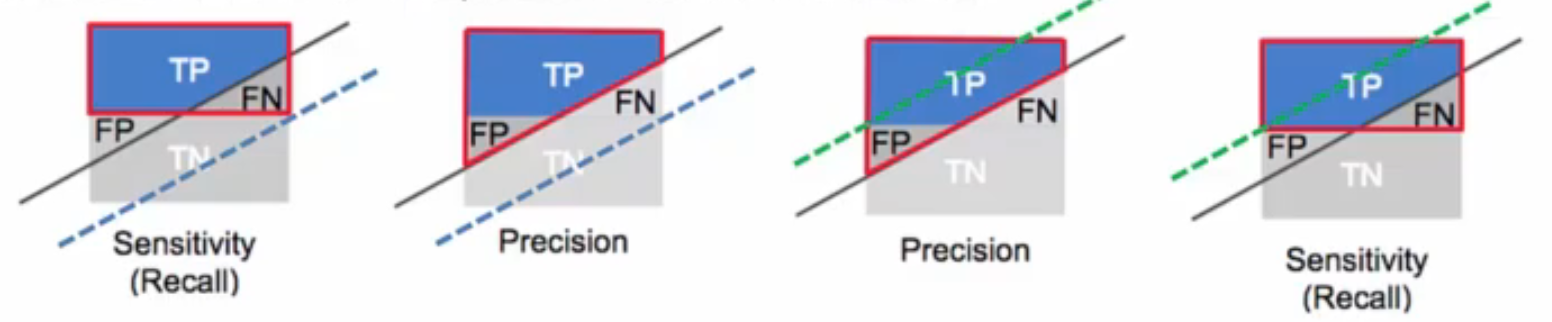 Precision vs. Recall Trade-off
Precision vs. Recall Trade-off
https://www.edwith.org/deep-learning-2023/lecture/1475084
ROC and AUC
Model은 test set에 대하여 실수값 혹은 확률 예측값을 계산합니다. 그 후 해당 에측값과 cut point(분류 임계치)를 비교합니다. Cut off보다 크면 positive value, 작으면 negative value로 분류합니다. 다양한 문제에서 각 문제의 목적과 필요에 따라 서로 다른 cut point를 사용합니다. 만약 precision을 더 중요하게 생각한다면 예측값 배열에서 큰 값을 cut point로 설정하고, recall을 더 중요하게 생각한다면 작은 값을 cut point로 설정합니다. 따라서 cut point에 따라 다른 문제에서 각 model의 성능이 결정됩니다.
ROC는 receiver operating characteristic(수신기 조작 특성)의 약자로, 세계 2차대전 당시 적군의 레이더 신호를 분석하는 기술로 활용되었고 1960~70년대부터 심리학, 의학용 test 연구에 응용되기 시작했습니다. 그 후 본격적으로 machine learning 영역에도 응용되고 있습니다.
Model의 에측 결과를 기반으로 sample에 대해 예측값 순서를 매기고, 다양한 cut point에 따라 true positive rate(TPR, 참 양성률)과 false positive rate(FPR, 거짓 양성률) 값을 계산하여 x축과 y축에 그려넣으면 ROC curve가 완성됩니다.
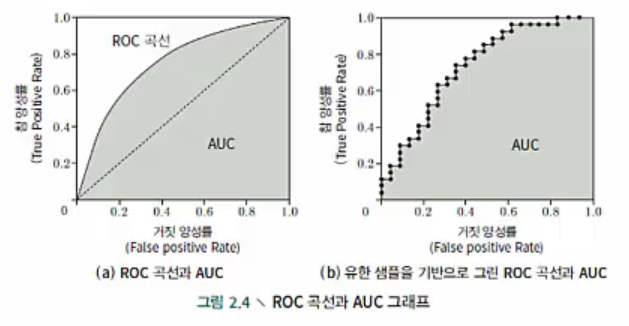 ROC and AUC
ROC and AUC
https://www.edwith.org/deep-learning-2023/lecture/1475084
Fig (a)에서 대각선은 ‘random prediction model’을 나타낸 것으로 무작위로 답을 선택했을 때 맞출 확률로 이해하면 되겠습니다. 좌표 위의 점 (0, 1)은 모든 positive value를 분류해 낸 ‘가장 이상적인 model’을 의미합니다. 현실에서는 test sample 개수가 많지 않을 때가 많으며, 제한된 data를 이용해 ROC graph를 그리면 유한한 개수의 좌표값을 얻게 됩니다. 이 때는 fig (a)와 같이 매끄러운 ROC curve는 그릴 수 없고 fig (b)와 같은 근사값을 얻을 수 있습니다.
만약 어떤 model의 ROC curve가 다른 ROC curve에 완전히 ‘포함’되는 경우, 후자가 전자보다 우수한 성능을 가진 model이라 할 수 있습니다. 하지만 두 model의 ROC curve에 교차가 발생한다면 한 눈에 우열을 가리기 어렵습니다. 이런 상황에서 비교적 합리적인 비교 방법은 ROC curve 아래의 면적을 비교하는 것이며, 이를 AUC(Area Under ROC Curve)라고 합니다.
Take Home Message
ML은 다양한 parameter로 구성되어 있고, testing error를 최소화하는 쪽으로 parameter를 최적화하여 model selection을 해야합니다. Testing은 training에 포함되면 안되므로, training set에서 일부를 testing에 사용하는데 이를 validation set라고 합니다. Validation set를 만드는데 사용하는 대표적인 방법은 cross validation입니다. Validation set에서 model의 성능을 측정하는 방법에는 단순한 accuracy 측정 뿐만 아니라 precision, recall, ACUT 등의 방법이 있습니다.
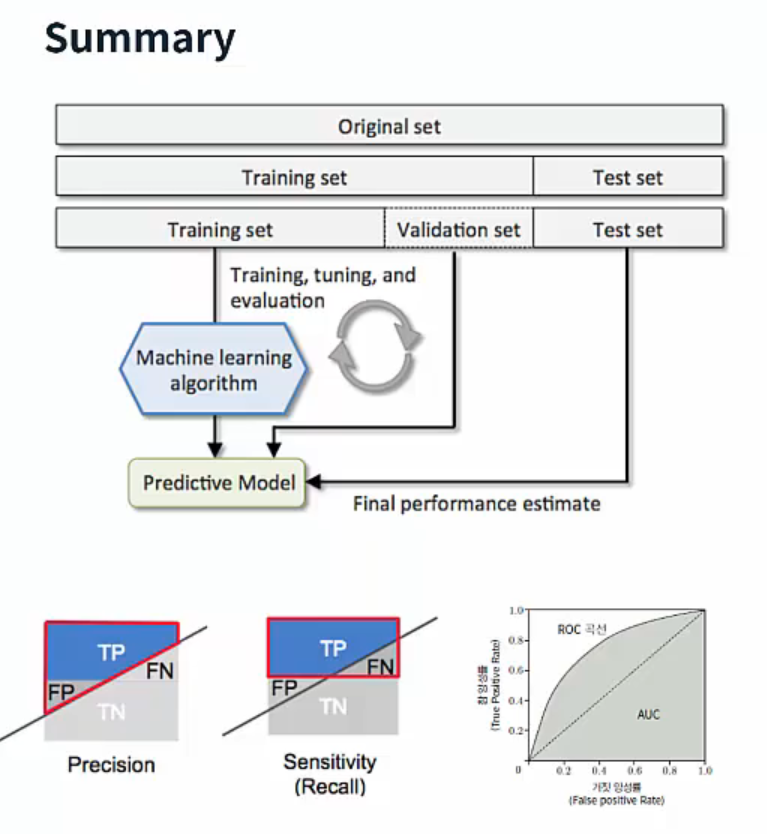 Summary
Summary
https://www.edwith.org/deep-learning-2023/lecture/1475084