본 post는 LAIAD에서 제공하는 부산대학교 이해승 교수님의 생물정보학을 위한 R프로그래밍을 정리한 내용입니다.
Intro
- R 프로그래밍의 데이터형과 연산에 대해 알아봅니다.
데이터의 저장과 처리
구조와 형태에 따라 데이터의 이름도 다릅니다.
- 변수
- 벡터(vector): 단일값들의 모임입니다. 데이터 구조의 가장 기본입니다.
- 배열(array) : 벡터를 행과 열로 구성한 구조입니다. 2차원: 행렬, 3차원: 배열
- 데이터프레임(dataframe): 서로 다른 데이터 형이 표 형태로 정리된 구조입니다. 각 속성의 크기가 같습니다.
- 리스트(list): 여러 데이터를 그룹화한 구조입니다. 각 속성의 크기가 달라도 됩니다.
데이터형: 숫자형, 문자형, 범주형, 논리형, 특수 상수 등
- 연산자: 산술(+, -, *, /), 비교(>, <), 논리 연산자(==, !=, !)
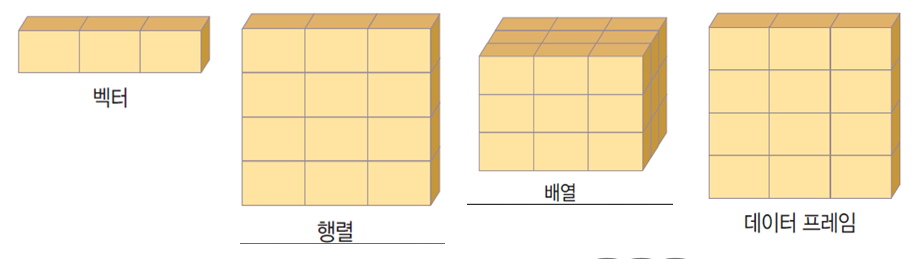 데이터 구조 간 관계
데이터 구조 간 관계
https://www.laidd.org/local/ubonline/view.php?id=181&group=1&returnurl=aHR0cHM6Ly93d3cubGFpZGQub3JnL2xvY2FsL3Vib25saW5lL2luZGV4LnBocD9vcmRlcnR5cGU9cmNfZCZrZXl3b3JkPSZwcm9ncmVzcyU1QiU1RD0xMyZlbnJvbF9zdGFydD0mZW5yb2xfZW5kPSZzdHVkeV9zdGFydD0mc3R1ZHlfZW5kPQ==
변수명을 생성할 때 몇 가지 규칙이 있습니다.
- 첫 글자는 반드시 영문자 또는 마침표만 사용 가능합니다.
- 두 번째 글자 이후로는 영문자, 숫자, 밑줄 사용 가능합니다.
- 대문자와 소문자를 구분합니다.
- 빈 칸은 사용 불가합니다.
변수에 값을 할당할 때 세 가지 방법이 있습니다.
1
2
3
4
5
6
7
8
9
10
11
x = 1
y = 2
# method1
z = x + y
# method2
z <- x+y
# method3
x + y -> z
R의 기본 데이터형은 다음과 같습니다.
| 데이터형 | 종류 |
|---|---|
| 숫자형 | int: 정수, num: 실수, cplx: 복소수 |
| 문자형 | chr: 작은따옴표나 큰따옴표로 묶어서 표기 |
| 범주형 | factor: 레벨에 따라 분류된 형태 |
| 논리형 | TRUE(T), FALSE(F) |
| 특수 상수 | NULL: 정의되지 않은 값, NA: 결측값, -Inf: 음의 무한대, Inf: 양의 무한대, NaN: 0/0, Inf/Inf 등과 같이 연산 불가능한 값 표시 |
기본 데이터형 실습 예제입니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
x = 5
y = 2
x/y
xi = 1 + 2i
yi = 1 - 2i
xi + yi
str = "Heool, World!"
str
blood.type = factor(c('A', 'B', 'O', 'AB'))
blood.type
T
F
xinf = Inf
yinf = Inf
xinf/yinf
데이터형을 확인하는 함수입니다.
| 함수 | 설명 |
|---|---|
| class(x) | R 객체지향 관점에서 x의 데이터형 |
| typeof(x) | R 언어 자체 관점에서 x의 데이터형 |
| is.integer(x) | x가 정수형이면 TRUE, 아니면 FALSE |
| is.numeric(x) | x가 실수형이면 TRUE, 아니면 FALSE |
| is.complex(x) | x가 복소수형이면 TRUE, 아니면 FALSE |
| is.character(x) | x가 문자형이면 TRUE, 아니면 FALSE |
| is.na(x) | x가 NA이면 TRUE, 아니면 FALSE |
데이터형을 변환하는 함수입니다.
| 함수 | 설명 |
|---|---|
| as.factor(x) | x를 범주형으로 변환 |
| as.integer(x) | x를 정수형으로 변환 |
| as.numeric(x) | x를 숫자형으로 변환 |
| as.character(x) | x를 문자형으로 변환 |
| as.matrix(x) | x를 행렬로 변환 |
| as.array(x) | x를 배열로 변환 |
산술 연산자는 다음과 같습니다.
| 연산자 | 설명 | 예 |
|---|---|---|
| + | 덧셈 | 5 + 2 |
| - | 뺄셈 | 5 - 2 |
| * | 곱셈 | 5 * 2 |
| / | 나눗셈(실수 나눗셈) | 5 / 2 |
| ^ 또는 ** | 지수승 | 5 ^ 2 |
| x %% y | x를 y로 나눈 나머지 (정수 나눗셈 나머지) | 5 %% 2 |
| x %/% y | x를 y로 나눈 몫 (정수 나눗셈 몫) | 5 %/% 2 |
비교, 논리 연산자는 다음과 같습니다.
| 연산자 | 설명 | 예 |
|---|---|---|
| < | 좌변이 작은(미만) | 5 < 5 |
| <= | 좌변이 작거나 같은(이하) | 5 <= 5 |
| > | 좌변이 큰(초과) | 5 > 5 |
| >= | 좌번이 크거나 같은(이상) | 5 >= 5 |
| == | 좌변과 우변이 같은 | 5 == 5 |
| != | 좌변과 우변이 다른 | 5 != 5 |
| !x | 부정(not) | !TRUE |
| x | y, x | | y | x or y(또는, 합집합) | TRUE | FALSE |
| x & y, x & & y | x and y(그리고, 교집합) | TRUE & FALSE |
| isTRUE(x) | x의 TRUE 여부 판단 | isTRUE(TRUE) |
연산자를 연달아 사용할 때 우선순위를 따릅니다.
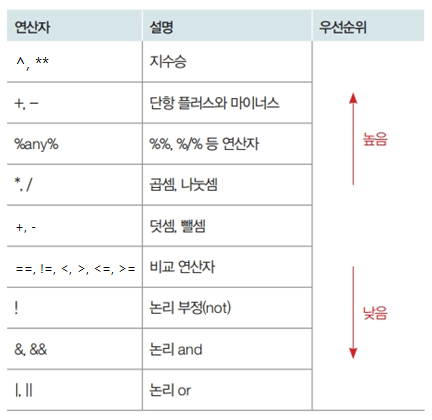 연산자 우선 순위
연산자 우선 순위
https://www.laidd.org/local/ubonline/view.php?id=181&group=1&returnurl=aHR0cHM6Ly93d3cubGFpZGQub3JnL2xvY2FsL3Vib25saW5lL2luZGV4LnBocD9vcmRlcnR5cGU9cmNfZCZrZXl3b3JkPSZwcm9ncmVzcyU1QiU1RD0xMyZlbnJvbF9zdGFydD0mZW5yb2xfZW5kPSZzdHVkeV9zdGFydD0mc3R1ZHlfZW5kPQ==
벡터
벡터는 여러 단일값을 하나의 변수명으로 저장할 수 있는 데이터형입니다.
벡터를 생성하는 여러 가지 방법이 있습니다.
- 벡터 생성 연산자: ‘:’
- vector 함수 이용: vector(length=n)
- c 함수 이용: c(1:5)
- seq 함수 이용: 순열 벡터를 생성합니다. seq(from=n, to=n, by=n)
- req 함수 이용: 반복 벡터를 생성합니다. rep(c(1:3), times=n), rep(c(1:3), each=n)
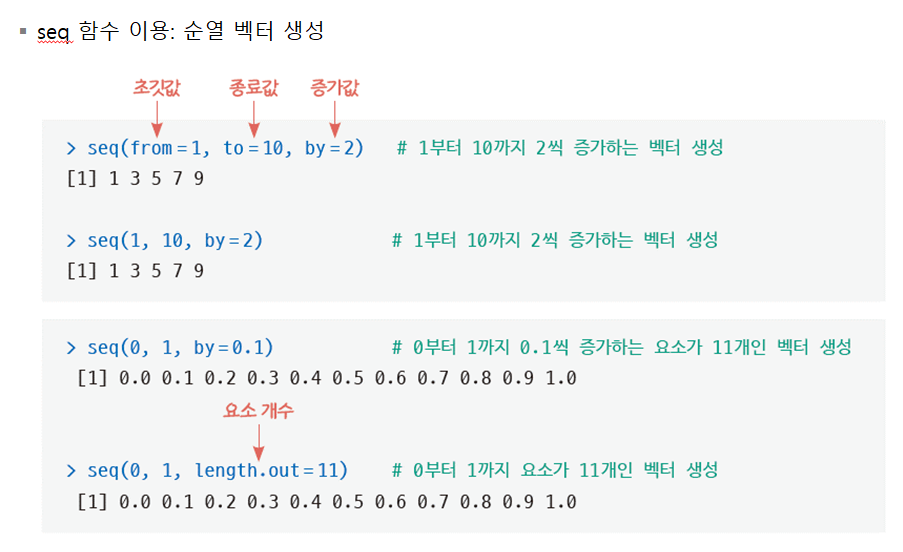 벡터 생성: seq 함수 이용
벡터 생성: seq 함수 이용
https://www.laidd.org/local/ubonline/view.php?id=181&group=1&returnurl=aHR0cHM6Ly93d3cubGFpZGQub3JnL2xvY2FsL3Vib25saW5lL2luZGV4LnBocD9vcmRlcnR5cGU9cmNfZCZrZXl3b3JkPSZwcm9ncmVzcyU1QiU1RD0xMyZlbnJvbF9zdGFydD0mZW5yb2xfZW5kPSZzdHVkeV9zdGFydD0mc3R1ZHlfZW5kPQ==
 벡터 생성: rep 함수 이용
벡터 생성: rep 함수 이용
https://www.laidd.org/local/ubonline/view.php?id=181&group=1&returnurl=aHR0cHM6Ly93d3cubGFpZGQub3JnL2xvY2FsL3Vib25saW5lL2luZGV4LnBocD9vcmRlcnR5cGU9cmNfZCZrZXl3b3JkPSZwcm9ncmVzcyU1QiU1RD0xMyZlbnJvbF9zdGFydD0mZW5yb2xfZW5kPSZzdHVkeV9zdGFydD0mc3R1ZHlfZW5kPQ==
벡터 연산과 관련된 실습 내용입니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
x = c(2, 4, 6, 8, 10)
length(x) # x 벡터의 길이를 구합니다.
x[1] # x 벡터의 1번 요소 값을 구합니다.
x[1, 2, 3] # x 벡터의 1, 2, 3번 요소 값을 구할 때 이와 같이 입력하면 에러가 발생합니다.
x[c(1, 2, 3)] # x 벡터의 1, 2, 3번 요소 값을 구할 때 벡터로 묶어줘야 합니다.
x[-c(1, 2, 3)] # x 벡터의 1, 2, 3번 요소를 제외한 값을 구합니다.
x[c(1:3)] # x 벡터의 1, 2, 3번 요소 값을 구합니다.
벡터 간 연산은 벡터의 길이가 같거나 요소 개수가 배수 관계에 있을 때 가능합니다.
1
2
3
4
5
6
7
8
9
10
11
12
x = c(1, 2, 3, 4)
y = c(5, 6, 7, 8)
z = c(3, 4)
w = c(5, 6, 7)
x + 2 # x 벡터의 개별 요소에 각각 2를 더합니다.
x + y # x 벡터와 y 벡터의 크기가 동일하므로 각 요소별로 더합니다.
x + z # x 벡터의 크기가 z 벡터 크기의 정수배(2배)이므로 크기가 작은 z 벡터 요소를 순환하며 x 벡터 각 요소에 더합니다.
x + w # x와 w 벡터의 크기가 정수배가 아니므로 연산에 에러가 발생합니다.
벡터 연산에 유용한 함수는 다음과 같습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
x = c(1:10)
x > 5 # x 벡터의 요소 값이 5보다 큰지 확인합니다.
all(x > 5) # x 벡터의 요소 값이 모두 5보다 큰지 확인합니다.
any(x > 5) # x 벡터의 요소 값 중 일부가 5보다 큰지 확인합니다.
a = c(1, 2, 3)
b = c(3, 4, 5)
c = c(3, 1, 2)
union(x, y) # 합집합
intersect(x, y) # 교집합
setdiff(x, y) # 차집합(x에서 y와 동일한 요소 제외하고 출력)
setequal(x, y) # x와 y에 동일한 요소가 있는지 비교
Take Home Message
- R에서 사용하는 데이터형과 연산에 대해 알아보았습니다.