본 post는 LAIAD에서 제공하는 부산대학교 이해승 교수님의 생물정보학을 위한 R프로그래밍을 정리한 내용입니다.
Intro
- R 프로그래밍의 데이터형과 연산에 대해 알아봅니다.
배열
배열은 열과 행으로 구성된 데이터형입니다. array 함수는 N차원 배열을 생성합니다.
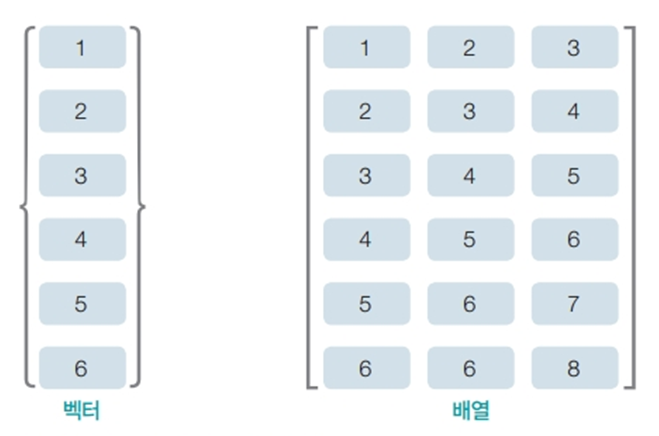 벡터와 배열의 구성 형태
벡터와 배열의 구성 형태
https://www.laidd.org/local/ubonline/view.php?id=181&group=1&returnurl=aHR0cHM6Ly93d3cubGFpZGQub3JnL2xvY2FsL3Vib25saW5lL2luZGV4LnBocD9vcmRlcnR5cGU9cmNfZCZrZXl3b3JkPSZwcm9ncmVzcyU1QiU1RD0xMyZlbnJvbF9zdGFydD0mZW5yb2xfZW5kPSZzdHVkeV9zdGFydD0mc3R1ZHlfZW5kPQ==
1
2
3
4
5
x = array(1:5, c(2,4))
# [,1] [,2] [,3] [,4]
# [1,] 1 3 5 2
# [2,] 2 4 1 3
matrix 함수는 2차원 배열을 생성합니다. nrow는 행의 수를 결정합니다. byrow는 데이터를 행 단위로 배치할지 여부를 결정합니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
x = 1:12
[1] 1 2 3 4 5 6 7 8 9 10 11 12
matrix(x, nrow=3)
# [,1] [,2] [,3] [,4]
# [1,] 1 4 7 10
# [2,] 2 5 8 11
# [3,] 3 6 9 12
matrix(x, nrow=3, byrow=T)
# [,1] [,2] [,3] [,4]
# [1,] 1 2 3 4
# [2,] 5 6 7 8
# [3,] 9 10 11 12
cbind, rbind 함수는 열, 행 단위로 묶어 배열을 생성합니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
v1 = c(1, 2, 3, 4)
v2 = c(5, 6, 7, 8)
v3 = c(9, 10, 11, 12)
cbind(v1, v2, v3)
# v1 v2 v3
#[1,] 1 5 9
#[2,] 2 6 10
#[3,] 3 7 11
#[4,] 4 8 12
rbind(v1, v2, v3)
# [,1] [,2] [,3] [,4]
#v1 1 2 3 4
#v2 5 6 7 8
#v3 9 10 11 12
배열(행렬) 연산자는 다음과 같습니다.
| 연산자 | 설명 |
|---|---|
| +, - | 행렬의 덧셈과 뺄셈 |
| * | R에서의 행렬 곱셈</br>(각 열별 곱셈) |
| %*% | 수학적인 행렬 곱셈 |
| t(), apem() | 전치 행렬 |
| solve() | 역행렬 |
| det() | 행렬식 |
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
x = array(1:4, dim=c(2,2))
y = array(5:8, dim=c(2,2))
x
# [,1] [,2]
#[1,] 1 3
#[2,] 2 4
y
# [,1] [,2]
#[1,] 5 7
#[2,] 6 8
x*y
# [,1] [,2]
#[1,] 5 21
#[2,] 12 32
x%*%y
# [,1] [,2]
#[1,] 23 31
#[2,] 34 46
t(x)
# [,1] [,2]
#[1,] 1 2
#[2,] 3 4
solve(x)
# [,1] [,2]
#[1,] -2 1.5
#[2,] 1 -0.5
det(x)
#[1] -2
배열에서 사용 가능한 유용한 함수가 있습니다.
apply 함수는 배열의 행 또는 열별로 함수를 적용합니다.
dim 함수는 배열의 크기(차원의 수)를 출력합니다.
sample 함수는 벡터나 배열에서 샘플 데이터를 추출합니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
x = array(1:12, c(3,4))
x
# [,1] [,2] [,3] [,4]
#[1,] 1 4 7 10
#[2,] 2 5 8 11
#[3,] 3 6 9 12
apply(x, 1, mean)
#[1] 5.5 6.5 7.5
apply(x, 2, mean)
#[1] 2 5 8 11
apply(x, 1, mean) # 가운데 값이 1이면 함수를 행별로 적용
#[1] 5.5 6.5 7.5
apply(x, 2, mean) # 가운데 값이 2이면 함수를 열별로 적용
#[1] 2 5 8 11
dim(x)
#[1] 3 4
sample(x) # 배열 요소를 임의로 섞어 추출
#[1] 7 5 3 11 9 1 6 10 2 12 4 8
sample(x, 10) # 배열 요소 중 10개를 골라 추출
#[1] 10 2 8 7 6 1 4 3 11 12
sample(x, 10, prob=c(1:12)/24) # 각 요소별 추출 확률을 달리할 수 있음
#[1] 7 11 4 8 2 10 9 6 12 5
sample(10) # 단순히 숫자만 사용하여 샘플을 만들 수 있음
#[1] 4 10 1 9 8 3 6 5 7 2
데이터프레임
데이터프레임은 가장 흔히 쓰이는 표 형태의 데이터 구조를 가집니다. 행렬과 달리 여러 데이터형을 혼합하여 저장할 수 있습니다. 리스트와 달리 행의 수를 일치시켜서 저장해야 합니다.
데이터프레임을 생성할 때 data.frame 함수를 이용합니다.
1
2
3
4
5
6
7
8
9
10
name = c("철수", "춘향", "길동")
age = c(22, 20, 25)
gender = factor(c("M", "F", "M"))
blood.type = factor(c("A", "O", "B"))
patients = data.frame(name, age, gender, blood.type)
patients
# name age gender blood.type
#1 철수 22 M A
#2 춘향 20 F O
#3 길동 25 M B
데이터프레임 요소에 접근할 때는 $, [, ], 조건식 등을 이용합니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
patients$name # name 속성 값 출력
#[1] "철수" "춘향" "길동"
patients[1, ] # 1행 값 출력
# name age gender blood.type
#1 철수 22 M A
patients[, 2] # 2열 값 출력
#[1] 22 20 25
patients[3, 1] # 3행 1열 값 출력
#[1] "길동"
patients[patients$name=="철수", ] # 환자 중 철수에 대한 정보 추출
# name age gender blood.type
#1 철수 22 M A
patients[patients$name=="철수", c("name", "age")] # 철수 이름과 나이 정보만 추출
# name age
#1 철수 22
데이터프레임에 사용할 수 있는 유용한 함수가 있습니다.
attach/detach 함수는 데이터프레임의 속성명을 변수명으로 변경합니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
head(cars) # cars 데이터셋 확인. head 함수의 기본 기능은 앞 6개 데이터를 추출함
# speed dist
#1 4 2
#2 4 10
#3 7 4
#4 7 22
#5 8 16
#6 9 10
speed # speed 변수가 독립적으로 존재하지 않기 때문에 에러 발생
#Error: object 'speed' not found
attach(cars) # attach 함수를 통해 cars의 각 속성을 변수로 이용하게 함
speed # speed라는 변수명을 직접 이용할 수 있음
# [1] 4 4 7 7 8 9 10 10 10 11 11 12 12 12 12 13 13 13 13 14 14 14 14 15 15 15 16 16 17 17 17 18 18 18 18 19 19 19 20 20 20 20 20 22 23 24 24 24 24 25
detach(cars) # detach 함수를 통해 cars의 각 속성을 변수로 사용하는 것을 해제함
speed # detach 실행 후 더이상 cars 속성인 speed를 사용하지 못함
#Error: object 'speed' not found
with 함수는 데이터프레임에 다양한 함수를 적용할 수 있습니다.
1
2
3
4
5
6
7
8
9
10
11
mean(cars$speed) # 데이터 속성을 이용해 함수 적용
#[1] 15.4
max(cars$speed) # 데이터 속성을 이용해 함수 적용
#[1] 25
with(cars, mean(speed)) # with 함수를 이용해 함수 적용
#[1] 15.4
with(cars, max(speed)) # with 함수를 이용해 함수 적용
#[1] 25
subset 함수는 데이터프레임에서 일부 데이터만 추출할 수 있습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
subset(cars, speed>20) # 속도가 20 초과인 데이터만 추출
# speed dist
#44 22 66
#45 23 54
#46 24 70
#47 24 92
#48 24 93
#49 24 120
#50 25 85
subset(cars, speed>20, select= -c(dist)) # 속도가 20 초과인 데이터 중 dist를 제외한 데이터만 추출
# speed
#44 22
#45 23
#46 24
#47 24
#48 24
#49 24
#50 25
subset(cars, speed>20, select=c(dist)) # 속도가 20 초과인 dist 데이터만 추출, 여러 열 선택은 c() 안을 ,로 구분
# dist
#44 66
#45 54
#46 70
#47 92
#48 93
#49 120
#50 85
리스트
리스트는 서로 다른 데이터형을 갖는 자료 구조를 포함할 수 있습니다. 데이터프레임보다 넓은 의미의 데이터 모임입니다. 데이터프레임과 달리 모든 속성의 크기가 같을 필요는 없습니다.
리스트를 생성할 때 list 함수를 이용할 수 있습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
patients = data.frame(name=c("철수", "춘향", "길동"), age=c(22, 20, 25), gender=factor(c("M", "F", "M")), blood.type=factor(c("A", "O", "B")))
no.patients = data.frame(day=c(1:6), no=c(50, 60, 55, 52, 65, 58))
listPatients = list(patients, no.patients) # 데이터를 단순히 추가
listPatients
#[[1]]
# name age gender blood.type
#1 철수 22 M A
#2 춘향 20 F O
#3 길동 25 M B
#[[2]]
# day no
#1 1 50
#2 2 60
#3 3 55
#4 4 52
#5 5 65
#6 6 58
listPatients = list(patients=patients, no.patients=no.patients) # 각 데이터에 이름을 부여하면서 추가
listPatients
#$patients
# name age gender blood.type
#1 철수 22 M A
#2 춘향 20 F O
#3 길동 25 M B
#$no.patients
# day no
#1 1 50
#2 2 60
#3 3 55
#4 4 52
#5 5 65
#6 6 58
리스트 요소에 접근할 때 $, [[ ]]를 이용합니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
listPatients$patients # 요소명 입력
# name age gender blood.type
#1 철수 22 M A
#2 춘향 20 F O
#3 길동 25 M B
listPatients[[1]] # 인덱스 입력
# name age gender blood.type
#1 철수 22 M A
#2 춘향 20 F O
#3 길동 25 M B
listPatients[["patients"]] # 요소명을 ""에 입력
# name age gender blood.type
#1 철수 22 M A
#2 춘향 20 F O
#3 길동 25 M B
리스트에 사용할 수 있는 유용한 함수가 있습니다.
lapply/sapply 함수는 리스트 요소에 다양한 함수를 적용합니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
lapply(listPatients$no.patients, mean) # no.patients 요소의 평균을 구함
#$day
#[1] 3.5
#$no
#[1] 56.66667
lapply(listPatients$patients, mean) # patients 요소의 평균을 구함. 숫자 형태가 아닌 것은 평균이 구해지지 않음
#$name
#[1] NA
#$age
#[1] 22.33333
#$gender
#[1] NA
#$blood.type
#[1] NA
#Warning messages:
#1: In mean.default(X[[i]], ...) :
# 인자가 수치형 또는 논리형이 아니므로 NA를 반환합니다
#2: In mean.default(X[[i]], ...) :
# 인자가 수치형 또는 논리형이 아니므로 NA를 반환합니다
#3: In mean.default(X[[i]], ...) :
# 인자가 수치형 또는 논리형이 아니므로 NA를 반환합니다
sapply(listPatients$no.patients, mean)
# day no
# 3.50000 56.66667
sapply(listPatients$no.patients, mean, simplify=F) # sapply()의 simplify 옵션을 F로 하면 lapply()와 동일한 결과 반환함
#$day
#[1] 3.5
#$no
#[1] 56.66667
Take Home Message
- R에서 사용하는 데이터형과 연산에 대해 알아보았습니다.