본 post는 LAIAD에서 제공하는 부산대학교 이해승 교수님의 생물정보학을 위한 R프로그래밍을 정리한 내용입니다.
Intro
- R 프로그래밍의 데이터 시각화를 학습합니다.
데이터 시각화
데이터의 의미를 통찰하고 전달하는 가장 좋은 방법은 시각적으로 표현하는 것입니다. 데이터 시각화는 데이터를 관찰하는 과정에서 선택 사항이 아니라 반드시 거쳐야 하는 필수 과정입니다.
기술 통계량은 데이터 특성을 파악하기 위해 데이터를 요약한 값입니다. 기술 통계량 관련 함수는 다음과 같습니다.
| 함수 | 기능 | x <- 1:10 일 때 결과 |
|---|---|---|
| mean | 평균, 절사평균 | mean(x) -> 5.5 |
| var | 분사 | var(x) -> 9.166667 |
| sd | 표준편차 | sd(x) -> 3.02765 |
| sum | 합 | sum(x) -> 55 |
| min | 최소 | min(x) -> 1 |
| max | 최대 | max(x) -> 10 |
| range | 범위, 최소와 최댓값을 출력 | range(x) -> c(1, 10) |
| median | 중앙값(중위수) | median(x) -> 5.5 |
| quantile | 분위수 | - |
| IQR | 사분위수 범위 | IQR(x) -> 4.5 |
| cor | 상관계수 | - |
예제 데이터를 통해 데이터 시각화의 필요성을 알아보겠습니다. anscombe 예제 데이터에서 통계 지표와 분석 수치만으로 비교해보면 네 개의 데이터 셋은 거의 동일하다고 판단할 수 있습니다. 하지만 그래프로 나타내보면 서로 다른 분포를 가진 데이터임을 알 수 있습니다. 이처럼 데이터 시각화를 통해 데이터를 파악하는 것은 매우 중요합니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
anscombe
# x1 x2 x3 x4 y1 y2 y3 y4
#1 10 10 10 8 8.04 9.14 7.46 6.58
#2 8 8 8 8 6.95 8.14 6.77 5.76
#3 13 13 13 8 7.58 8.74 12.74 7.71
#4 9 9 9 8 8.81 8.77 7.11 8.84
#5 11 11 11 8 8.33 9.26 7.81 8.47
#6 14 14 14 8 9.96 8.10 8.84 7.04
#7 6 6 6 8 7.24 6.13 6.08 5.25
#8 4 4 4 19 4.26 3.10 5.39 12.50
#9 12 12 12 8 10.84 9.13 8.15 5.56
#10 7 7 7 8 4.82 7.26 6.42 7.91
#11 5 5 5 8 5.68 4.74 5.73 6.89
apply(anscombe, 2, mean) # 평균
# x1 x2 x3 x4 y1 y2 y3 y4
#9.0 9.0 9.0 9.0 7.5 7.5 7.5 7.5
apply(anscombe, 2, var) # 분산
# x1 x2 x3 x4 y1 y2 y3 y4
#11.00 11.00 11.00 11.00 4.13 4.13 4.12 4.12
cor(anscombe$x1, anscombe$y1) # 상관관계(상관계수)
#[1] 0.816
cor(anscombe$x2, anscombe$y2)
#[1] 0.816
cor(anscombe$x3, anscombe$y3)
#[1] 0.816
cor(anscombe$x4, anscombe$y4)
#[1] 0.817
par(mfrow = c(2, 2))
plot(anscombe$x1, anscombe$y1)
plot(anscombe$x2, anscombe$y2)
plot(anscombe$x3, anscombe$y3)
plot(anscombe$x4, anscombe$y4)
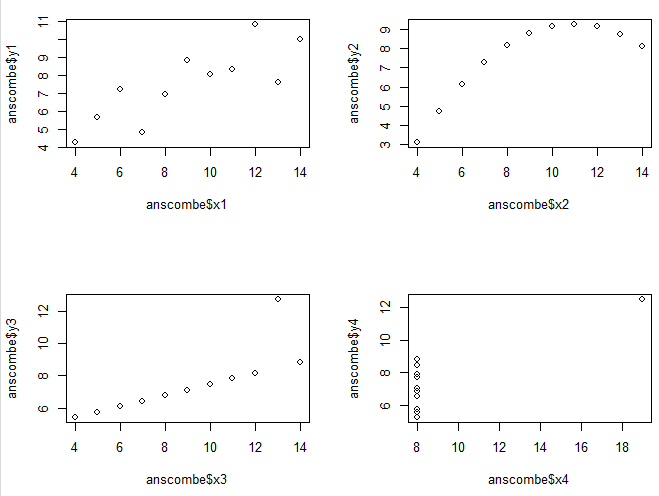 데이터 시각화 필요성
데이터 시각화 필요성
https://www.laidd.org/local/ubonline/view.php?id=181&group=1&returnurl=aHR0cHM6Ly93d3cubGFpZGQub3JnL2xvY2FsL3Vib25saW5lL2luZGV4LnBocD9vcmRlcnR5cGU9cmNfZCZrZXl3b3JkPSZwcm9ncmVzcyU1QiU1RD0xMyZlbnJvbF9zdGFydD0mZW5yb2xfZW5kPSZzdHVkeV9zdGFydD0mc3R1ZHlfZW5kPQ==
데이터 시각화의 기본 기능
데이터 시각화는 많은 양의 데이터를 올바로 해석할 수 있게 해주는 동시에 효과적으로 관찰할 수 있도록 도와줍니다.
데이터 시각화의 효과는 다음과 같습니다.
직관(insight)을 얻을 수 있습니다.
핵심을 명확하게 이해할 수 있습니다.
평균적인 경향과 더불어 이상값(outlier)도 발견할 수 있습니다.
데이터에서 문제를 빨리 찾아낼 수 있습니다.
| 조건에 맞는 요소를 추출하는 방법 | 형식 |
|---|---|
| []에 행/열 조건 명시 | 변수명[행 조건식, 열 조건식] |
| if문 활용 (if / else if / else) | if(조건식) 표현식 |
| ifelse문 활용 | ifelse(조건식, 참인 경우 반환값, 거짓인 경우 반환값) |
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
### []에 행/열 조건 명시
## 벡터의 경우
test = c(15, 20, 30, NA, 45) # 벡터 생성
test[test<40] # 값이 40 미만인 요소 추출
#[1] 15 20 30 NA
test[test%%3!=0] # 값이 3으로 나누어 떨어지지 않는 요소 추출
#[1] 20 NA
test[is.na(test)] # NA인 요소 추출
#[1] NA
test[!is.na(test)] # NA가 아닌 요소 추출
#[1] 15 20 30 45
test[test%%2==0&!is.na(test)] # 2의 배수면서 NA가 아닌 요소 추출
#[1] 20 30
## 데이터프레임인 경우
characters = data.frame(name=c("길동", "춘향", "철수"), age=c(30, 16, 21), gender=factor(c("M", "F", "M"))) # 데이터프레임 생성
characters
# name age gender
#1 길동 30 M
#2 춘향 16 F
#3 철수 21 M
characters[characters$gender=="F",] # 성별이 여성인 행 추출
# name age gender
#2 춘향 16 F
characters[characters$age<30&characters$gender=="M", ] # 30살 미만의 남성 행 추출
# name age gender
#3 철수 21 M
### if문 사용 (if, else if, else)
## 두 가지 조건 분기가 필요한 경우
x = 5
if(x %% 2==0) {
print('x는 짝수') # 조건식이 참일 때 수행
} else {
print('x는 홀수') # 조건식이 거짓일 때 수행
}
#[1] "x는 홀수"
## 세 가지 조건 분시가 필요한 경우
x = -1
if(x>0) {
print('x is a positive value.') # x가 0보다 크면 출력
} else if(x<0) {
print('x is a negative value.') # 위 조건을 만족하지 않고 x가 0보다 작으면 출력
} else {
print('x is zero.') # 위 조건을 모두 만족하지 않으면 출력
}
#[1] "x is a negative value."
## ifelse문 사용
x = c(-5:5)
options(digits=3) # 숫자 표현 시 유효자릿수를 3자리로 설정
sqrt(x)
# [1] NaN NaN NaN NaN NaN 0.00 1.00 1.41 1.73 2.00 2.24
#Warning message:
#In sqrt(x) : NaNs produced
sqrt(ifelse(x>=0, x, NA)) # NaN이 발생하지 않게 음수면 NA로 표시
# [1] NA NA NA NA NA 0.00 1.00 1.41 1.73 2.00 2.24
데이터 정제를 위한 반복문
데이터 검토 시 반복적으로 값을 변경하면서 사용해야 하는 경우에 사용합니다. R에서 제공하는 반복문은 repeat, while, for 문이 있습니다.
| 반복문 | 의미 |
|---|---|
| repeat {</br> 반복 수행할 문장</br>} | 블록 안의 문장을 반복해서 수행합니다. |
| while(조건식) {</br> 조건식이 참일 때 수행할 문장</br>} | 조건식이 참일 때 블록 안의 문장을 수행합니다. |
| for(변수 in 데이터) {</br> 반복 수행할 문장 } | 데이터의 각 요소를 변수에 할당하면서 각각에 대해 블록 안의 문장을 수행합니다. |
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
## 1부터 10까지 수를 1씩 증가시키기
for(i in 1:10) {
print(i)
}
#[1] 1
#[1] 2
#[1] 3
# ...
## 구구단 2~9단 만들기
for(i in 2:9) {
for(j in 1:9) {
print(paste(i, "X", j, "=", i*j))
}
}
#[1] "2 X 1 = 2"
#[1] "2 X 2 = 4"
#[1] "2 X 3 = 6"
# ...
## 1에서 10까지의 수 중 짝수만 출력하기
for(i in 1:10) {
if(i%%2==0) {
print(i)
}
}
#[1] 2
#[1] 4
#[1] 6
#[1] 8
#[1] 10
## 1에서 10까지의 수 중 소수 출력하기
for(i in 1:10) {
check=0
for(j in 1:i) {
if(i%%j==0) {
check=check+1
}
}
if(check==2) {
print(i)
}
}
#[1] 2
#[1] 3
#[1] 5
#[1] 7
사용자 정의 함수: 원하는 기능 묶기
함수는 입력과 출력간의 관계식을 의미합니다. 사용자의 목적에 맞는 다양한 함수를 만들 수 있습니다.
사용자 정의 함수의 구조는 아래와 같습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
#함수명 = function (전달인자1, 전달인자2, ...) {
# 함수 동작 시 수행할 코드
# return(반환값)
#}
## 계승을 구하는 함수
fact = function(x) { # 함수의 이름은 fact, 입력은 x
fa = 1 # 계승값을 저장할 변수
while(x>1) { # x가 1보가 큰 동안 반복
fa=fa*x # x 값을 fa에 곱한 후 fa에 다시 저장
x=x-1 # x 값을 1 감소
}
return(fa) # 최종 계산된 fa 반환
}
fact(5) # 5 factorial을 계산한 결과 출력
#[1] 120
결측값 처리
데이터에는 결측값(missing value)이 존재할 수 있는데, 데이터 중 고의 또는 실수로 누락된 값을 의미합니다. 결측값을 그대로 놔둔 채 데이터 가공을 하면 결과값에 오류가 뜨거나 잘못된 연산이 수행될 수 있으므로 정제과정에서 적절한 처리가 필요합니다.
결측값 처리에는 다음과 같은 방법이 있습니다.
| 방법 | 설명 |
|---|---|
| is.na 함수 이용 | NA인 데이터가 있으면 T,</br>없으면 F로 나타냅니다. |
| na.omit 함수 이용 | NA인 데이터를 제거합니다.</br>즉, NA가 포함된 행을 지웁니다. |
| 함수의 속성 이용 | na.rm=T로 하여 함수 수행 시 NA를 제외합니다. |
1
2
3
4
5
6
7
8
9
10
11
## na.omit 함수 이용
air_narm = na.omit(airquality)
mean(air_narm$Ozone)
#[1] 42.1
## 함수 속성인 na.rm=T 설정
mean(airquality$Ozone, na.rm=T)
#[1] 42.1
이상값 처리
결측값과 더불어 데이터에는 논리적 혹은 통계학적으로 이상한 데이터가 입력되어 있을 수 있습니다. 이러한 데이터를 이상값(outlier)이라 합니다. 통계학에서 이상값이란 다른 관측값과 멀리 떨어진 관측값입니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
patients = data.frame(
name=c("환자1", "환자2", "환자3", "환자4", "환자5"),
age=c(22, 20, 25, 30, 27),
gender=factor(c("M", "F", "M", "K", "F")),
blood.type=factor(c("A", "O", "B", "AB", "C")))
patients
# name age gender blood.type
#1 환자1 22 M A
#2 환자2 20 F O
#3 환자3 25 M B
#4 환자4 30 K AB
#5 환자5 27 F C
# 성별에 K, 혈액형에 c 값은 명백한 이상값입니다.
# 성별에서 이상값 제거
patients_outrm = patients[patients$gender=="M"|patients$gender=="F", ]
patients_outrm
# name age gender blood.type
#1 환자1 22 M A
#2 환자2 20 F O
#3 환자3 25 M B
#5 환자5 27 F C
# 성별과 혈액형에서 이상값 제거
patirents_outrm1 = patients[
(patients$gender=="M"|patients$gender=="F") &
(patients$blood.type=="A"|patients$blood.type=="B"|patients$blood.type=="O"|patients$blood.type=="AB"), ]
patirents_outrm1
# name age gender blood.type
#1 환자1 22 M A
#2 환자2 20 F O
#3 환자3 25 M B
좀 더 실질적인 데이터를 활용하여 이상값을 처리해 봅니다. 실제 데이터에서는 이상값을 정의하기 모호한 경우가 많습니다. 이 때 boxplot을 활용하여 정상값과 이상값을 구분할 수 있습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
boxplot(airquality[, c(1:4)]) # Ozone, Solar.R, Wind, Temp에 대한 boxplot
boxplot(airquality[, 1])$stats
# [,1]
#[1,] 1.0 -> 이 값 미만은 이상값으로 분류할 수 있음
#[2,] 18.0
#[3,] 31.5
#[4,] 63.5
#[5,] 122.0 -> 이 값 초과는 이상값으로 부류할 수 있음
air = airquality # 임시 저장 변수로 airquality 데이터 복사
table(is.na(air$Ozone)) # Ozone의 현재 NA 개수 확인
#FALSE TRUE
# 116 37
## 이상값을 NA로 처리한 후 NA를 제거함
air$Ozone = ifelse(air$Ozone<1|air$Ozone>122, NA, air$Ozone)
table(is.na(air$Ozone))
#FALSE TRUE
# 114 39
# NA 제거
air_narm = air[!is.na(air$Ozone), ]
mean(air_narm$Ozone)
#[1] 40.2
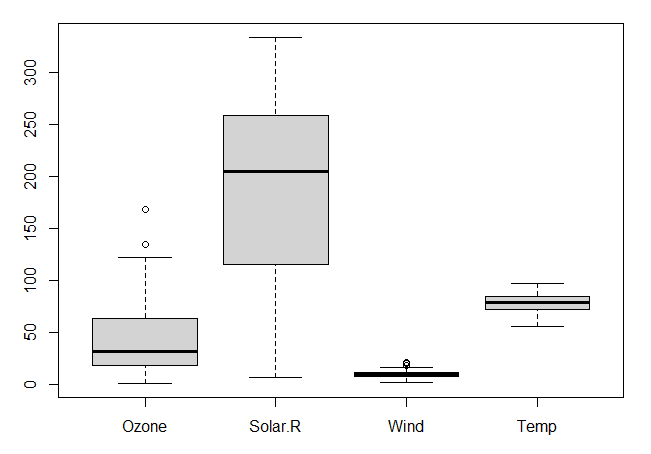 boxplot
boxplot
https://www.laidd.org/local/ubonline/view.php?id=181&group=1&returnurl=aHR0cHM6Ly93d3cubGFpZGQub3JnL2xvY2FsL3Vib25saW5lL2luZGV4LnBocD9vcmRlcnR5cGU9cmNfZCZrZXl3b3JkPSZwcm9ncmVzcyU1QiU1RD0xMyZlbnJvbF9zdGFydD0mZW5yb2xfZW5kPSZzdHVkeV9zdGFydD0mc3R1ZHlfZW5kPQ==
Take Home Message
- R 프로그래밍의 데이터 취득과 정제에 대해 알아보고 실습을 통해 학습했습니다.