본 post는 국가생명연구자원정보센터(KOBIC) 주관 서울대학교 의과대학 최무림 교수님의 WES 기초편 강의를 정리한 내용입니다.
Intro
WES 데이터 처리 단계와 주요 parameter를 소개합니다. WES 데이터의 질적 평가를 할 수 있습니다. WES 데이터 처리를 위한 파이프라인을 소개합니다. WES 데이터 처리의 예시를 수행합니다.
WES 데이터 처리 단계
Read alignment
bwa mem 주로 사용합니다.
Removing PCR duplicates
PCR 과정에서 발생하는 duplicate를 확인하고 제거하는 과정입니다. PCR duplicates는 biological duplicates와 다르며 임의로 중복 생산된 상태이므로 이를 제거하는 과정이 필요합니다.
picard를 주로 사용합니다.
![Post-Image]() PCR duplicates
PCR duplicates
www.edwith.org/wes-beginnerVariant calling
gatk Haplotypecaller를 주로 사용합니다.
Variant annotation
SnpEff를 주로 사용합니다.
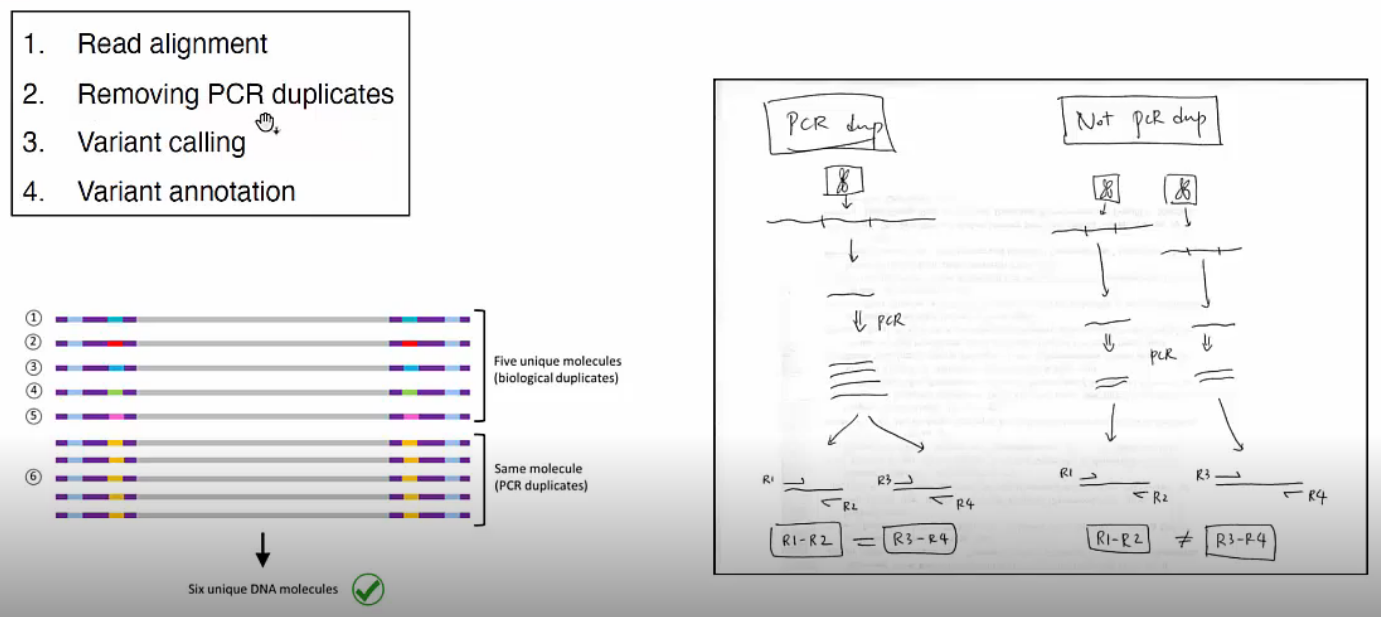 PCR duplicates
PCR duplicatesWES 데이터의 각종 parameter
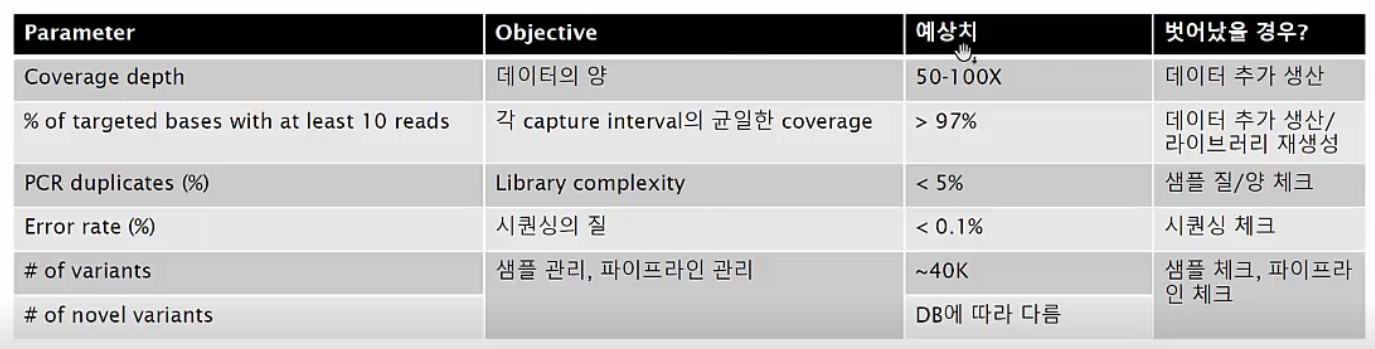 Parameters of WES data
Parameters of WES data
www.edwith.org/wes-beginner
WES 데이터 분석 파이프라인
 GATK Best Practice
GATK Best Practice
www.edwith.org/wes-beginner
WES 분석 파이프라인은 GATK best practice가 가장 잘 알려져 있고 손쉽게 따라할 수 있습니다.
Summary
- WES 분석 파이프라인은 GATK best practice가 잘 구축되어 있고 주로 사용합니다.